Dear PyTorch Community,
I am a student and currently working on a project where I use a CNN to predict a single label (regression).
I have 7 3-channel images, I transform them to 1-channel images with transforms.Grayscale(num_output_channels=1) (similar to MNIST) then I stack them upon each other as an input to my CNN model. 50 such images (should be around 300 but for this example) together contribute to one label (a decimal value example 0.87) i.e. my input to CNN is torch.Size([50, 7, 150, 150]) and my label size is torch.Size([1, 1])
I am writing in response to a persistent error and a unceasing problem that I am facing with my model and code: my model seems to be lazy and always output the mean value (this eventually decreases the loss but that not what I want). This is how it looks:
Predictions vs Outputs
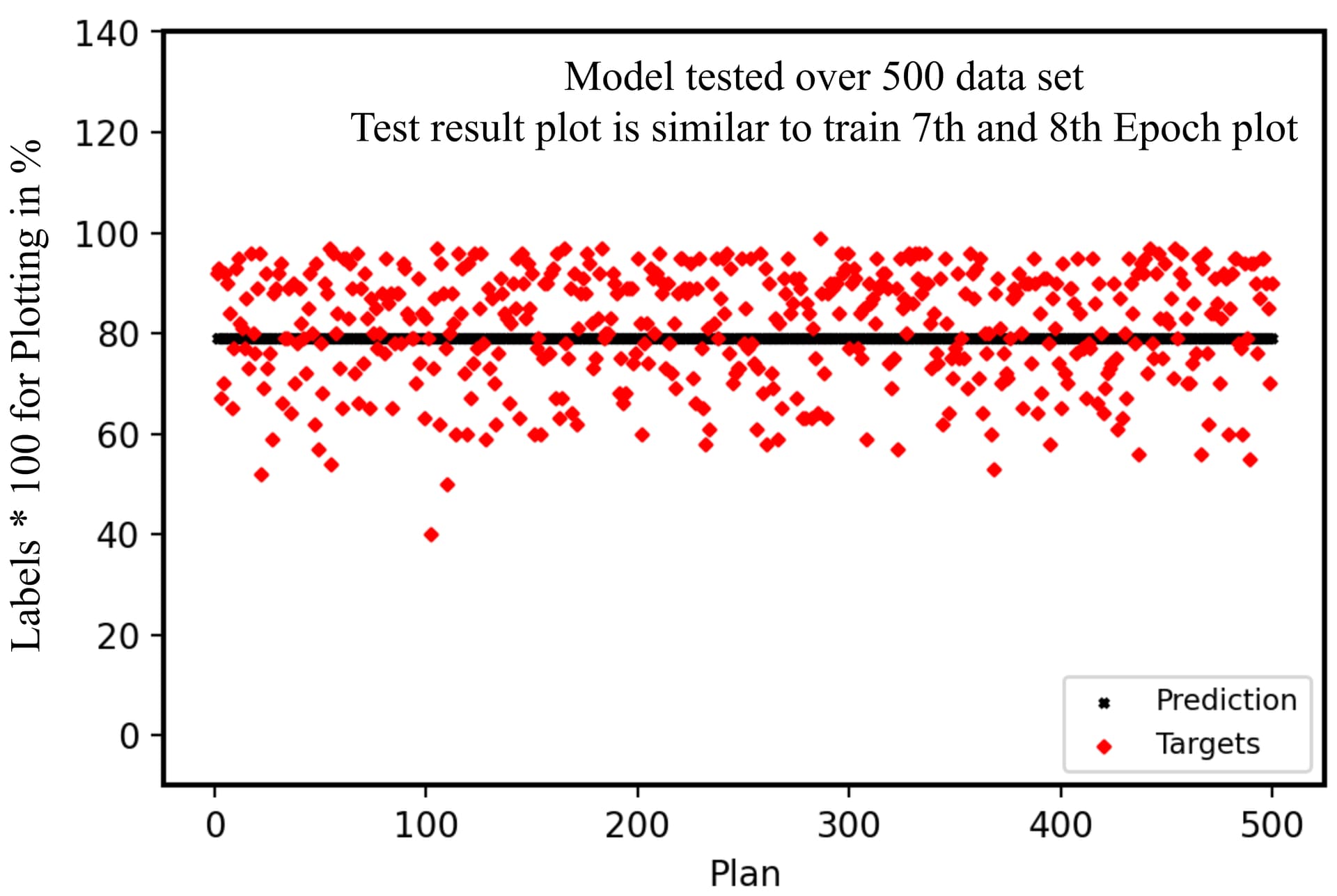
Train vs Validation Loss: both get really low upto the same level and stay steady after that, no more decay after the 6th Epoch until 8th.
This is how my model looks like:
class CNNFC(nn.Module):
def __init__(self, sequence_size, label_size, num_layers, train_CNN = True):
super(CNNFC, self).__init__()
self.train_CNN = train_CNN
self.conv1 = nn.Conv2d(7, 128, 5, 1)
self.pool = nn.MaxPool2d(2 , 2)
self.conv2 = nn.Conv2d(128, 256, 5, 2)
self.conv3 = nn.Conv2d(256, 512, 5, 2)
self.adPooling = AdaptiveAvgPool2d(output_size=(1, 1))
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.3)
self.conv2_bn = nn.BatchNorm2d(128)
self.features = []
self.linearCNN1 = nn.Linear(3*3*512, 2304)
self.linearCNN2 = nn.Linear(2304, 1152)
self.linearCNN3 = nn.Linear(1152,512)
self.linearCNN4 = nn.Linear(512,128)
self.linearCNN5 = nn.Linear(128,64)
self.linearCNN6 = nn.Linear(64,32)
self.linearCNN7 = nn.Linear(32,16)
self.linearCNN8 = nn.Linear(16,1)
self.sequence_size = sequence_size
self.label_size = label_size
self.num_layers = num_layers
self.fc = nn.Linear(sequence_size, 16)
self.fc2 = nn.Linear(16, 8)
self.fc3 = nn.Linear(8, label_size)
self.fc4 = nn.Linear(2, label_size)
def forward(self, images):
out_features = self.conv1(images)
out_features = relu(out_features)
out_features = self.pool(out_features)
out_features = self.conv2(out_features)
out_features = relu(out_features)
out_features = self.pool(out_features)
out_features = self.conv3(out_features)
out_features = relu(out_features)
out_features = self.pool(out_features)
out_features1 = out_features.view(-1, 3*3*512)
out_features = self.linearCNN1(out_features1)
out_features = relu(out_features)
del out_features1
out_features = self.linearCNN2(out_features)
out_features = relu(out_features)
out_features = self.linearCNN3(out_features)
out_features = relu(out_features)
out_features = self.linearCNN4(out_features)
out_features = relu(out_features)
out_features = self.linearCNN5(out_features)
out_features = relu(out_features)
out_features = self.linearCNN6(out_features)
out_features = relu(out_features)
out_features = self.linearCNN7(out_features)
out_features = relu(out_features)
out_features = self.linearCNN8(out_features)
out_features = relu(out_features)
# out_features = self.dropout(out_features)
out_features = out_features.unsqueeze(0)
out_features = out_features.squeeze(2)
out_features = self.fc(out_features)
out_features = relu(out_features)
out_features = self.fc2(out_features)
out_features = relu(out_features)
out_features = self.fc3(out_features)
return out_features
This is how I train:
# -*- coding: utf-8 -*-
all imports...
def train():
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
np.random.seed(0)
torch.backends.cudnn.benchmark = True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# normalizing over the mean and std for 7 channels makes the loss.item NAN
transform2 = transforms.Compose([
transforms.Normalize(mean, std),
]
)
#hyper parameters
# batch_size = 1
num_layers = 1
learning_rate = 1e-5
num_epochs = 8
sequence_size = 50
#label_size = 10
label_size = 1 # (0.9 or 0.0)
img_dir = "/image_directory"
# # data with 5000 set
Traindata_directory = "Data/"
Testdata_directory = "DataTest/"
dataset_train = DataLoader(img_dir, Traindata_directory )
data_loader = DataLoader(dataset = dataset_train,
shuffle = True)
dataset_test = DataLoader_test(img_dir,Testdata_directory)
data_loader_test = DataLoader(dataset = dataset_test,
shuffle = True)
model = CNNFC(sequence_size, label_size, num_layers).to(device)
criterion = torch.nn.SmoothL1Loss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
model.train()
running_loss = 0.0
running_validationloss = 0.0
# useful lengths
total_steps = len(data_loader.dataset)
train_len = len(data_loader.dataset)
test_len = len(data_loader_test.dataset)
# Lists for plotting the graph
complete_loss_Train = []
complete_loss_Test = []
collect_label = []
collect_outputs = []
collect_loss = []
TrainLossList = []
ValidLossList = []
torch.cuda.empty_cache()
for epoch in range(num_epochs):
for idx, (inputs,labels) in enumerate(data_loader):
inputs = inputs.squeeze(0).float().to(device)
labels = labels.squeeze(0).float().to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward(loss)
# gradient clipping
torch.nn.utils.clip_grad_norm(model.parameters(), max_norm=1)
# Adjusts the weights
optimizer.step()
complete_loss_Train.append(round(loss.item(),4))
running_loss += loss.item()
if epoch == num_epochs-1:
collect_label.append(round(labels.item(), 2)*100)
collect_outputs.append(round(outputs.item(),2)*100)
collect_loss.append(round(loss.item(),4))
# Enter after 1/5 of epoch
if (idx+1) % 1000 == 0:
print (f'Epoch [{epoch+1}/{num_epochs}], Step [{idx+1}/{total_steps}], Average Loss: {running_loss/1000:.4f}')
print (f'Epoch [{epoch+1}/{num_epochs}], Step [{idx+1}/{total_steps}], Loss: {loss.item():.4f}')
print ("train outputs:", outputs, " corresponding labels:", labels)
TrainLossList.append(running_loss/1000)
running_loss = 0.0
# validate after 1/5 epoch
with torch.no_grad():
# lists to plot graphs for validation test
test_loss_epoch = []
collect_label_test = []
collect_outputs_test = []
for idx, (inputs_,labels_) in enumerate(data_loader_test):
inputs_test = inputs_.squeeze(0).float().to(device)
labels_test = labels_.squeeze(0).float().to(device)
outputs_test = model(inputs_test)
# append for plots
collect_label_test.append(round(labels_test.item(), 2)*100)
collect_outputs_test.append(round(outputs_test.item(),2)*100)
loss_test = criterion(outputs_test, labels_test)
# append for plots
test_loss_epoch.append(round(loss_test.item(),4))
complete_loss_Test.append(round(loss_test.item(),4))
running_validationloss += loss_test.item()
torch.cuda.empty_cache()
ValidLossList.append(running_validationloss/test_len)
print (f'Epoch [{epoch+k}/{num_epochs}], Average Valid Test Loss: {running_validationloss/test_len:.4f}')
print (f'Epoch [{epoch+k}/{num_epochs}], Valid Test Loss: {loss_test.item():.4f}')
# reset to 0
running_validationloss = 0.0
torch.cuda.empty_cache()
k=0
# Deleted the plotting commands...
running_loss_test = 0.0
complete_loss_Test = []
collect_label_test = []
collect_outputs_test = []
collect_loss_Test = []
# operations on the group set to test after the train is done
with torch.no_grad():
for idx, (inputs,labels) in enumerate(data_loader_test):
inputs = inputs.squeeze(0).float().to(device)
labels = labels.squeeze(0).float().to(device)
outputs = model(inputs)
loss_test = criterion(outputs, labels)
running_loss_test += loss_test.item()
# for plots
collect_label_test.append(round(labels.item(), 2)*100)
collect_outputs_test.append(round(outputs.item(),2)*100)
collect_loss_Test.append(round(loss_test.item(),4))
torch.cuda.empty_cache()
# Deleted the plotting commands...
if __name__ == "__main__":
train()
Based on some of the answers on the Pytorch forums:
- I tried lowering my learning rate (tried range
1e-2to1e-5) - Tried increasing the epochs (max 8 epochs so far)
- previously also tried Batch Normalization and Dropout
- Earlier I was using the output of my CNN as a input to GRU to control those 400 (many to one RNN architecture)
- I have also noticied whenever I normalize the data from transforms with my mean (i.e.
[0.0774, 0.0641, 0.0664, 0.0671, 0.0388, 0.0487, 0.1583]) and standard deviation (i.e.[0.1980, 0.1603, 0.1726, 0.1729, 0.1111, 0.1310, 0.3651]) I always get theloss.itemas NAN
All the mentioned approaches landed me to the same plots and predictions.
I would truly appreciate if anyone is willing to give suggestions, tips or solutions to this problem if they have encountered and solved this earlier.
Also please feel free to give me any feedback over what should I improve with this.
Thank you, best,
Pradnil