ex: 10 X 253 X 768 … This tensor X is from the output of an LSTM.
There is a another tensor Y, of shape:
batch_size X number_of_sequence X embedding_size
ex: 10 X 253 X 300 … This tensor Y is the output from an Embedding.
I need to work with these 2 tensors X and Y and feed this to an Attention network to match the sequence Y to each element in X. I need bit help as to which operations would be better to pack X and Y … I mean, if I do torch.cat((X, Y), dim=2) will this be a good idea?
The dimensions of these 2 tensors X and Y are different and for my case, I want the dimension of X. So, what I can do is put Y into an LSTM and get this as the same dimension as of X.
Then I can do a point-wise addition between X and Y to get an unified-weighted tensor.
Can you share will point-wise addition would be a good operation in this case? or there are other better operations?
I have different types of attention mechanisms. (one-directional, bi-directional etc)
similar to
Mostly, they create an affinity matrix with M x N (M = sequence length of X, N = sequence length of Y) by a dot (vector) product between X & Y and use this affinity matrix to summarise X and/or Y.
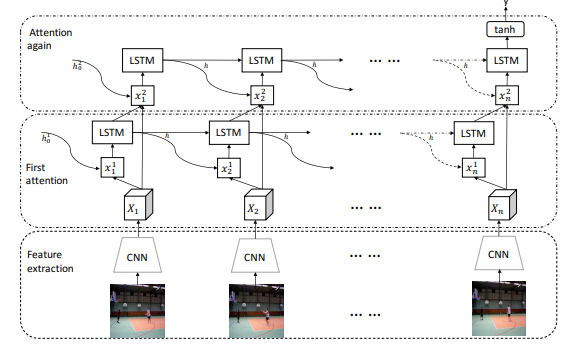
I am working on a question-answering task. Instead of CNN, the input is from a word embedding.
So, I have 2 tensors.
An output from an LSTM (in the figure attached, this is the output from LSTM in First attention to x2_1) that holds the representations of:
1.1 the input words (X_1) and other features.
1.2 the question embedding on the input words.
Let’s say this tensor is hidden_docs. The shape of this tensor is batch_size X sequence_length X hidden_size. For example, hiddens_docs = tensor(10, 253, 768)
X_1 is the input words representation.
Let’s say this tensor is x1_emb. The shape of this tensor is batch_size X sequence_length X embedding_size. For example, x1_emb = tensor(10, 253, 300)
I need to project x1_emb on hidden_docs to get a unified representation between hidden_docs and x1_emb. And this representation then needs to be feed into x2_1 (in the ‘Attention again’).
Currently, what I am doing is since the shape is different, I am passing the x1_emb into an LSTM and able to get the shape as = batch_size X sequence_length X hidden_size.
And then I am doing a point-wise addition operation between hidden_docs and x1_emb before passing the output to x2_1. Now here I am bit confused.
Is the operation - point-wise addition between these two tensors is right operations? are there other better operations to do to capture the better representations between hidden_docs and x1_emb?
I understand. I’m not sure if I could say what operations are right and wrong. In general, I have seen papers doing addition as well as dot product based attention mechanism. You can only evaluate it empirically I guess.