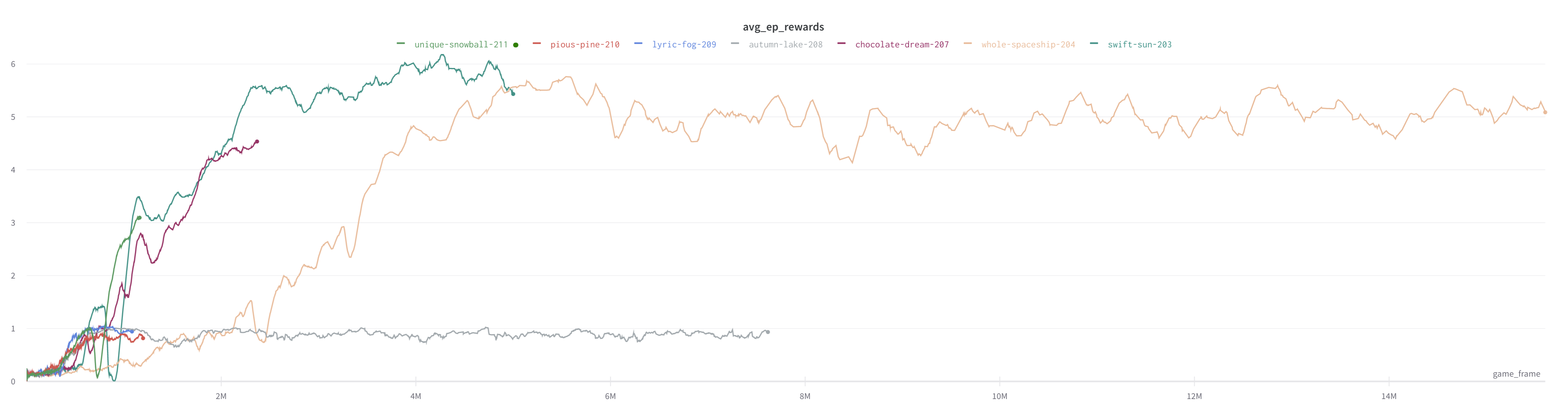
I’m trying to replicate the Mnih et al. 2015/Double DQN results on Atari Breakout but the per-episode rewards (where one episode is a single Breakout game terminating after loss of a single life) plateau after about 3-6M frames with a per-ep reward of around 5-6:
It would be really awesome if anyone could take a quick look here and check for any “obvious” problems. I tried to comment it fairly well and remove any irrelevant parts of code.
Things I have tried so far:
- DDQN instead of DQN
- Adam instead of RMSProp (training with Adam doesn’t even reach episode reward > 1, see gray line in plot above)
- various learning rates
- using exact hyperparams from the DQN, DDQN, Mnih et al 2015, 2013,… papers
- fixing lots of bugs
- training for more than 10M frames (most other implementations I have seen reach a reward about 10x mine after 10M frames)
My goal ist to fully implement Rainbow-DQN but I would like to get DDQN to work properly first.