What if I want to run my evaluation engine (which itself has event handlers) with my evaluation dataloader every 20 epochs of the training engine? Right now this isn’t possible, so I made a wrapper function that allows for this below. However, I was wondering if there was an ignite way of doing this? I couldn’t find any.
def _lf_two(
log_fn: Callable[[Engine, List[str]], None],
inner_engine: Engine,
loader: DataLoader,
**kwargs
) -> Callable[[Engine], Any]:
"""Returns a lambda calling custom log function with two engines (e.g. the training loop and validation loop)"""
return lambda outer_engine: log_fn(
inner_engine, loader, epoch_num=outer_engine.state.epoch, **kwargs
)
def run_engine_and_log_output(
engine: Engine, loader: DataLoader, fields: List[str], epoch_num=None,
) -> None:
engine.run(loader,max_epochs=1, epoch_length=10)
###Here i grab things from engine.state.output and do what i want###
trainer.add_event_handler(
Events.EPOCH_COMPLETED(every=20),
_lf_two(
run_engine_and_log_output,
evaluator,
val_loader))
Also, I was wondering if I then wanted to run the evaluation outside of the training loop, and this time with different event handlers, would best practice be to create two different evaluation engines? One to pass into the training loop event handler into (__lf_two()), and one to run after my train.run ?
Maybe I do not correctly understand the issue, but if you would like to run model evaluation every 20-th epochs and in the end of the training it is simply done like :
oh oops sorry I forgot to mention that I want score_function to running the evaluation loop once, because I want the MSE from that. However, in that case I need to pass in the evaluator engine somehow.
@pytorchnewbiescore_function option is used to save only the best N models.
To resume, there are two options how to save models:
either based on any event. For example in like previous answer, model is always saved every 50-th epochs no matter its quality.
either based on a score. For example, evaluator engine provides a metric score, thus on the moment to save or not a model, Checkpoint verifies the current score, compares with registered score(s) and decides if we need or not to save current model.
If you would like combine both, you need to provide your own score_function that would take into account event number and your score.
trainer = ...
evaluator = ...
def score_function(_):
# MAKE SURE THAT MSE SCORE IS AVAILABLE WHEN IT IS CALLED
mse = evaluator.state.metrics["mse"]
epoch = trainer.state.epoch
# Create your own logic when to save the model
# ... model with highest scores will be retained.
return some_score
to_save = {'model': model}
handler = Checkpoint(..., score_function=score_function, ...)
trainer.add_event_handler(Events.COMPLETED, handler)
HTH
PS. If you want just to display eval score in the filename while saving a model every 50 epochs, unfortunately, this should be done by overriding the way you write the file…
The problem is that it saves the first 5 models every 10 epochs, so the model at epoch 10,20,30,40,50 . However, it doesn’t then replace them as the training continues (although the mse does drop)…
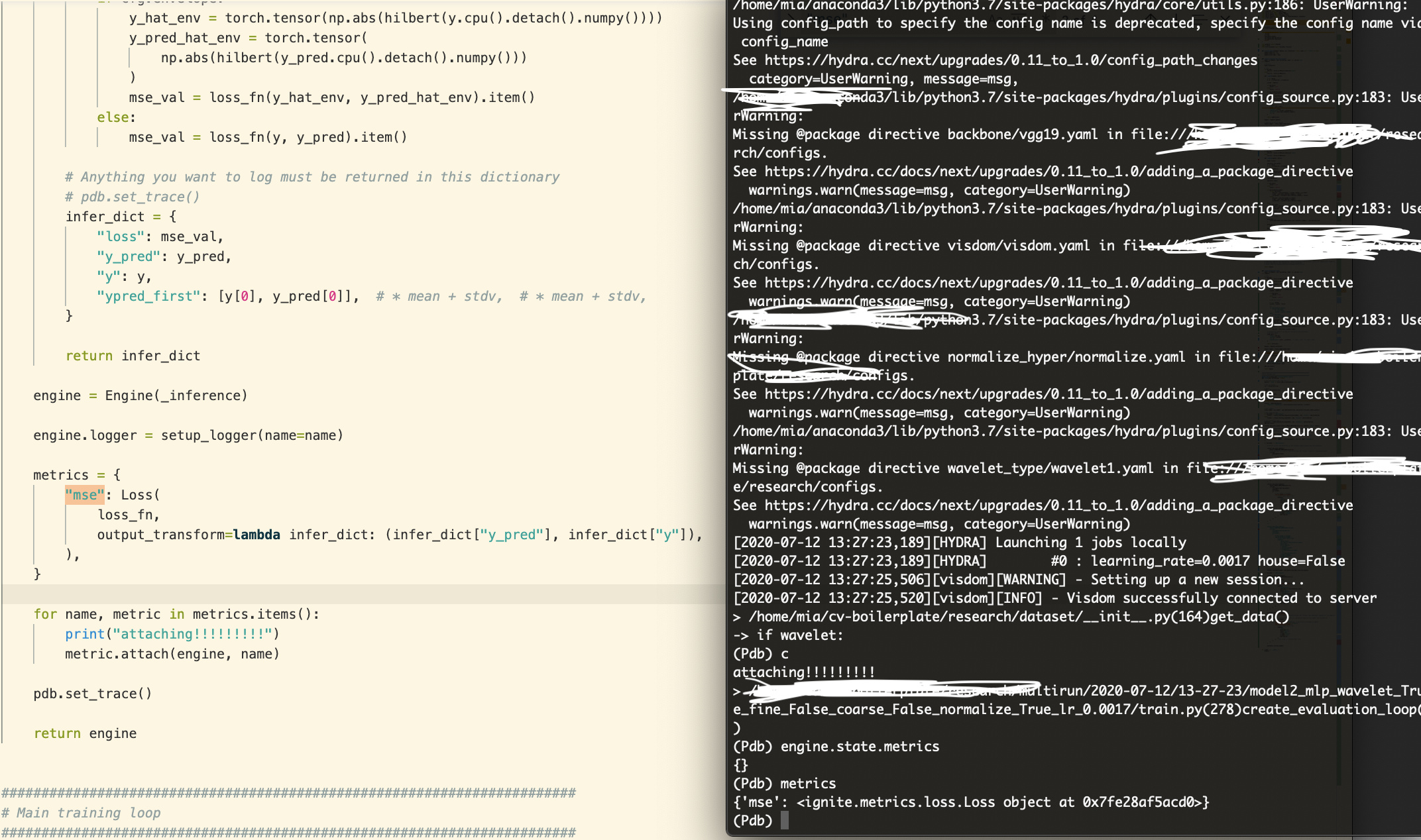
Hi again. I apologize in advance but I’ve tried solving this for 2 hours now. I’m not sure what I did but suddenly the attaching doesn’t work anymore. It doesn’t recognize “mse” :
Which is weird because it should since below is what I call in train():
And then here is a screenshot of the actual code of create_evaluation_loop(), as well as the terminal where I use pdb to show that despite the for loop where I attach running, afterwards the engine still doesn’t have anything in : engine.state.metrics …