Hi,
I am trying to re-implement this model using Pytorch Geometric, the model is based on the original one written with TensorFlow. The goal is to train a neural network to classify SAT formulas represented as graphs into two different classes (satisfiable and unsatisfiable formulas).
I’ve created a dataset of 200000 samples, based on the original code, and started training with a small subset of 2000 samples to check whether the network would work. What happens is that the training works when using a small subset of the dataset, but as soon as I increase the dimension of the dataset too much, the loss function doesn’t decrease anymore and the accuracy on the train dataset remains stable around 0.5. (The accuracy on the validation dataset is also always around 0.5 for all dataset dimension I’ve tested so far)
Here are a few plots of the loss function evolution with respect to a few different dataset sizes:
2K samples:
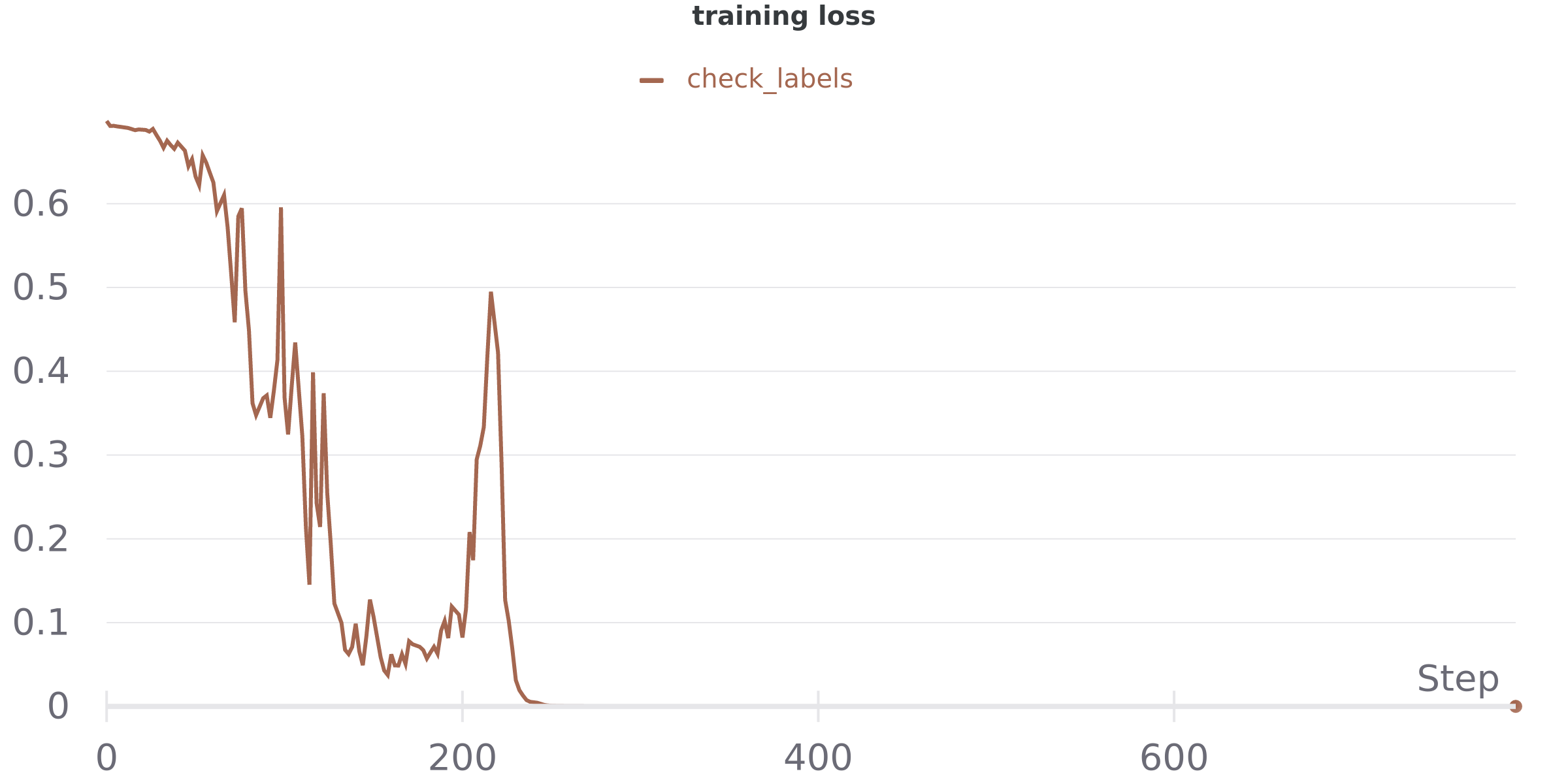
10K samples:
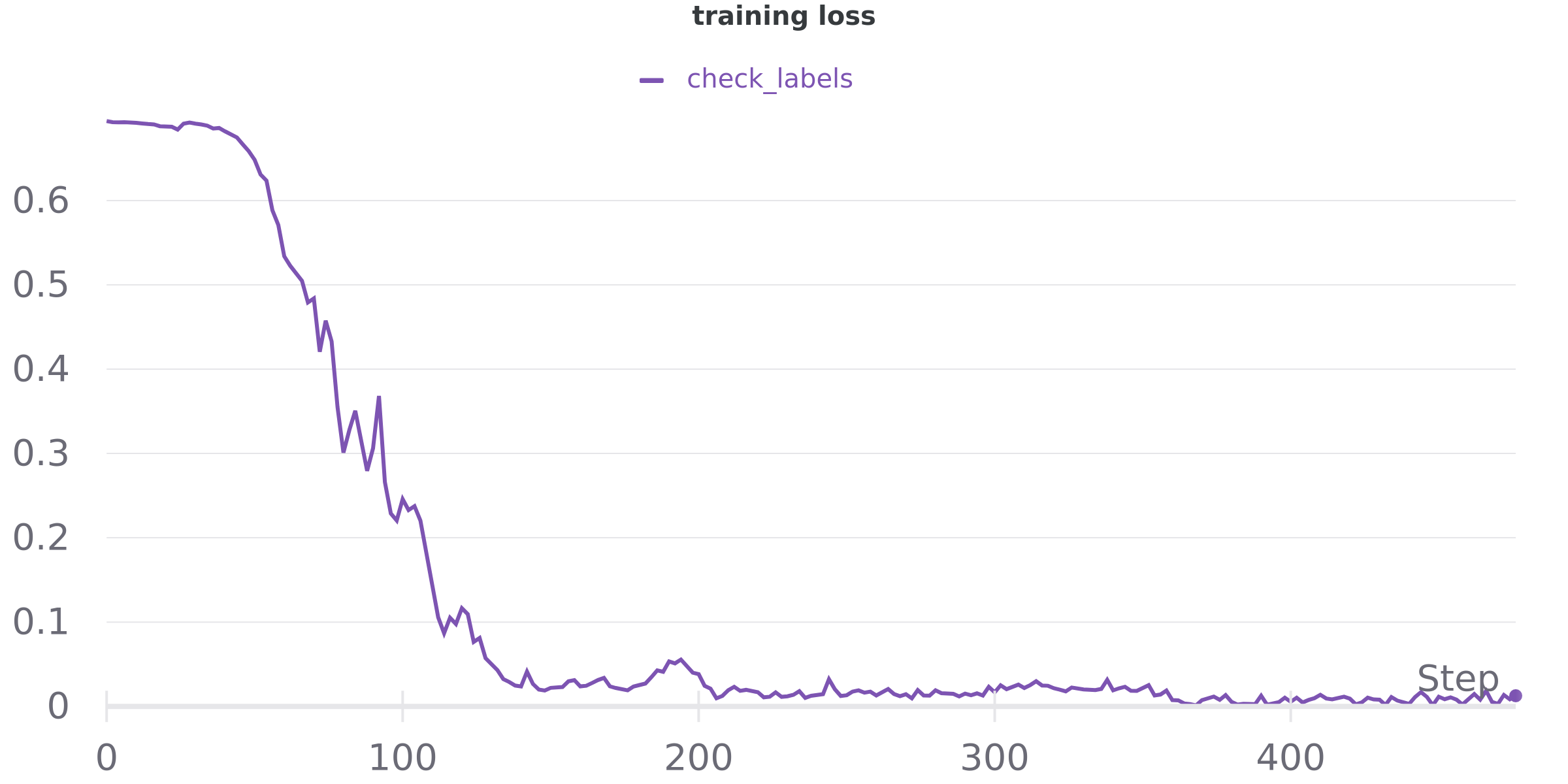
20K samples:
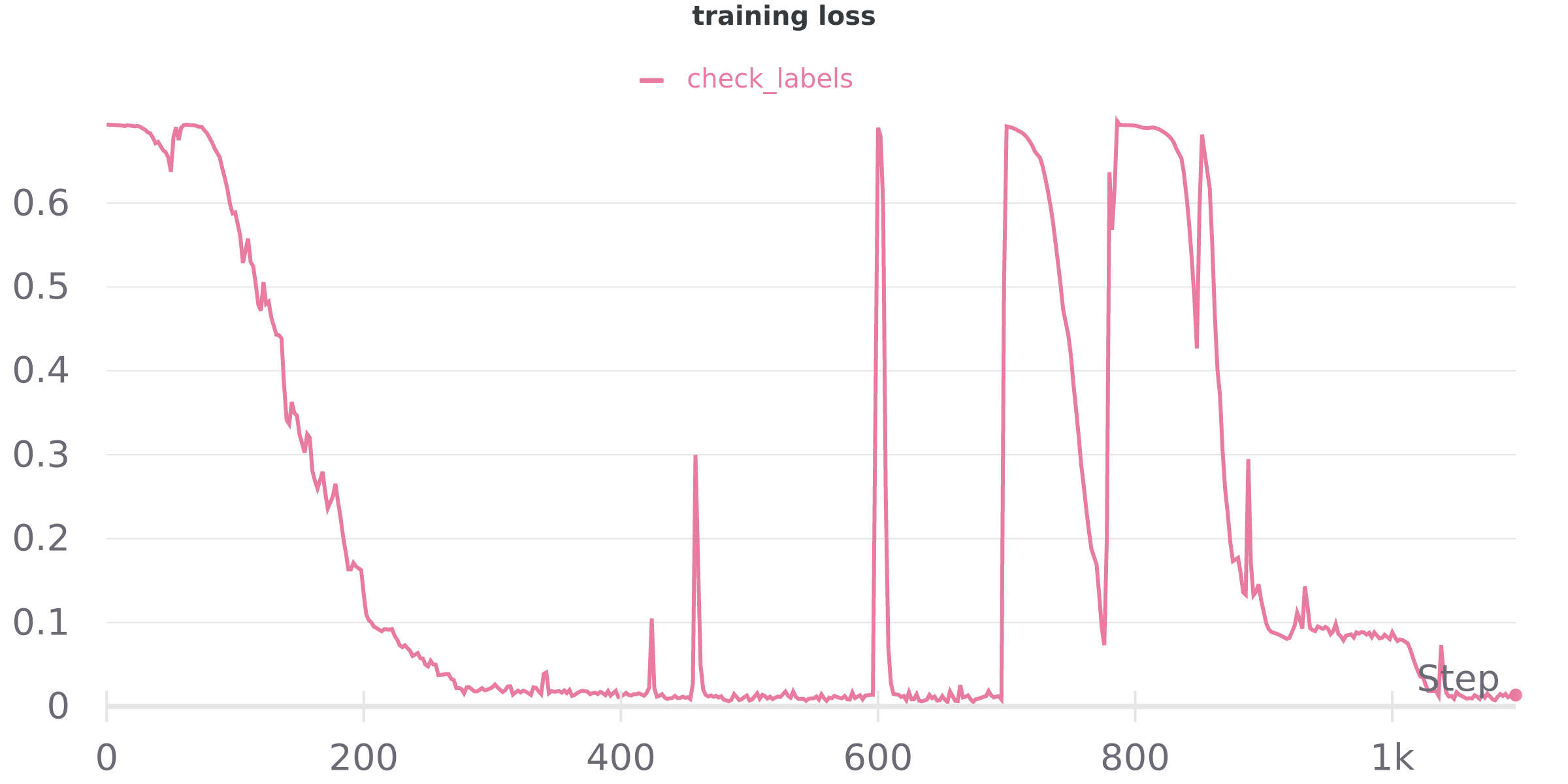
80K samples:
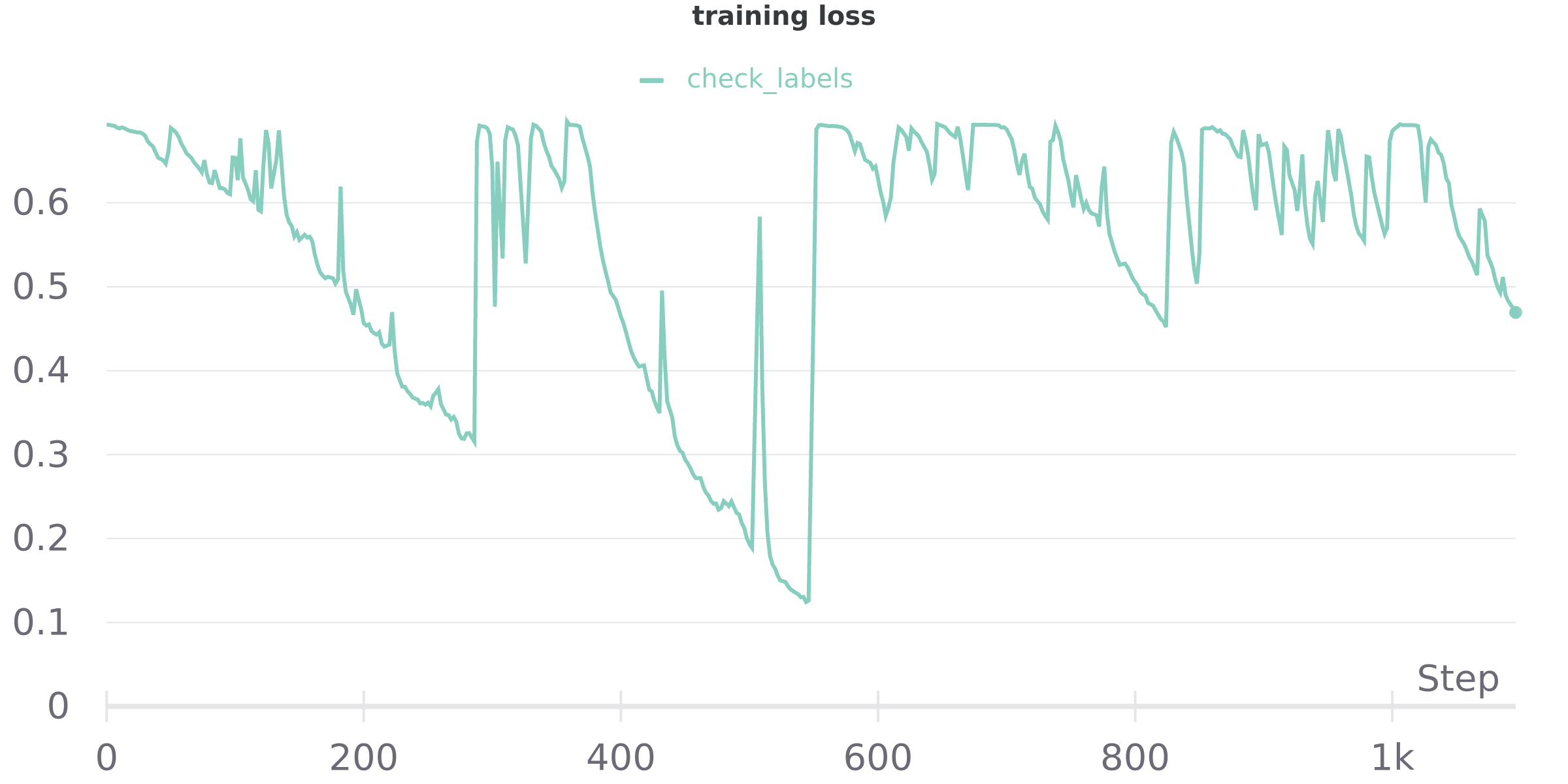
(when training on the whole dataset the loss function is basically constant at 0.69)
I am using the Adam optimizer with decreasing learning rate and binary cross entropy loss, as in the original code:
criterion = nn.BCEWithLogitsLoss()
lr_start = 2e-4
l2_weight = 1e-10 # L2 regularization weight
optimizer = optim.Adam(net.parameters(), lr=lr_start, weight_decay=l2_weight)
lr_decay = torch.tensor(0.99, dtype=torch.float64)
lr_decay_steps = torch.tensor(5, dtype=torch.float64)
gamma = torch.pow(lr_decay, torch.div(1, lr_decay_steps))
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma, last_epoch=-1)
Does anybody have an idea of what could cause this strange behavior? I am happy to post any additional information about my model, if needed.