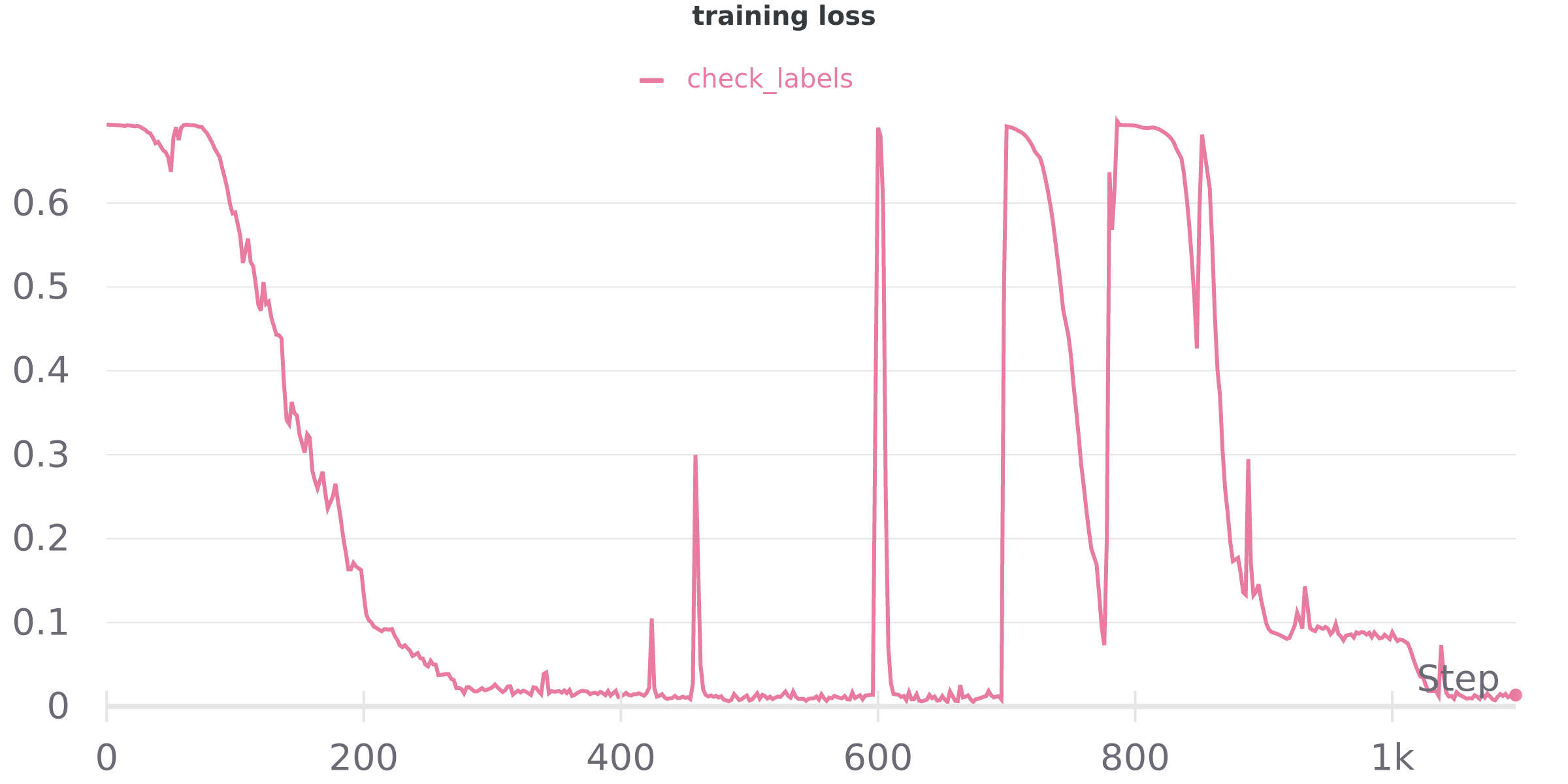
This is my training loop:
for epoch in range(load_epoch, load_epoch+n_epochs):
start = time.time()
loss, accuracy = train_epoch(net,
optimizer,
criterion,
device,
train_dataloader,
clip_val
)
end = time.time()
wandb.log({'training loss':loss})
wandb.log({'training accuracy':accuracy})
if (epoch+1) % print_every == 0:
logger.info(f"Training loss at epoch {epoch+1} : {loss}")
logger.info(f"Training accuracy at epoch {epoch+1} : {accuracy}")
logger.info(f"Runtime for one epoch : {end-start}")
if (epoch+1) % test_every == 0:
start = time.time()
val_loss, accuracy = test(net, device, test_dataloader, criterion)
end = time.time()
wandb.log({'validation loss':val_loss})
wandb.log({'validation accuracy':accuracy})
logger.info(f"Validation loss at epoch {epoch+1} : {val_loss}")
logger.info(f"Validation accuracy at epoch {epoch+1} : {accuracy}")
logger.info(f"Runtime for testing : {end-start}")
if (epoch+1) % save_every == 0:
logger.info(f"Saving training at epoch {epoch+1}")
torch.save({
'epoch': epoch+1,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict() if scheduler is not None else None,
'losses': losses,
'val_losses': val_losses,
'accuracies': accuracies,
'val_accuracies': val_accuracies
}, join(save_folder,"epoch_{:04d}.tar".format(epoch+1)))
where:
def train_epoch(net, optimizer, loss, device, dataloader, clip_val):
# training step on all dataset
net.train()
running_loss = 0.0
accuracy = 0.0
for batch in dataloader:
# zero the parameter gradients
optimizer.zero_grad()
batch.to(device)
pred = net(batch)
pred_binary = torch.sigmoid(pred.squeeze()) >= 0.5
pred_correct = pred_binary == batch.y.type_as(pred)
accuracy_temp = torch.sum(pred_correct)/len(pred_correct)
accuracy += accuracy_temp.item()
logit = loss(pred.squeeze(), batch.y.type_as(pred))
logit.backward()
if clip_val is not None:
torch.nn.utils.clip_grad_value_(net.parameters(), clip_val)
optimizer.step()
running_loss += logit.detach().item()
running_loss /= len(dataloader)
accuracy /= len(dataloader)
return running_loss, accuracy
def test(net, device, test_dataloader, val_criterion):
net.eval()
net = net.to(device)
with torch.no_grad():
val_loss = 0.0
accuracy = 0.0
for batch in test_dataloader:
batch.to(device)
pred = net(batch)
pred_binary = torch.sigmoid(pred.squeeze()) >= 0.5
pred_correct = pred_binary == batch.y.type_as(pred)
accuracy_temp = torch.sum(pred_correct)/len(pred_correct)
accuracy += accuracy_temp.item()
val_logit = val_criterion(pred.squeeze(),
batch.y.type_as(pred)).item()
val_loss += val_logit
val_loss /= len(test_dataloader)
accuracy /= len(test_dataloader)
return val_loss, accuracy
(I’ve tried with clip_val = 0.65 and clip_val = None)
I hope this is enough code, and I am happy to share more if it can be useful.