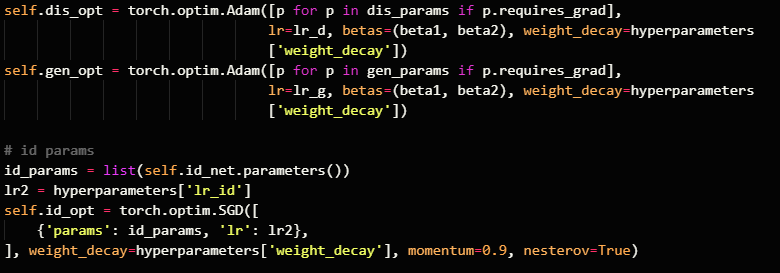
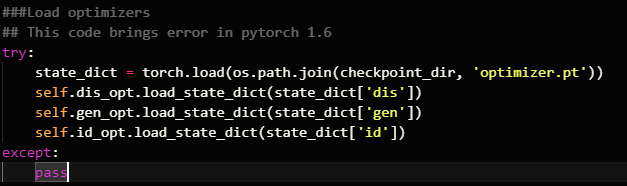
You could directly compare the differences in adam.py and would see that the bias_correction seems to be one significant change potentially causing the different behavior:
git diff v1.2.0 v1.6.0 -- torch/optim/adam.py
diff --git a/torch/optim/adam.py b/torch/optim/adam.py
index edcfcc26be..9d68613c64 100644
--- a/torch/optim/adam.py
+++ b/torch/optim/adam.py
@@ -37,6 +37,8 @@ class Adam(Optimizer):
raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))
+ if not 0.0 <= weight_decay:
+ raise ValueError("Invalid weight_decay value: {}".format(weight_decay))
defaults = dict(lr=lr, betas=betas, eps=eps,
weight_decay=weight_decay, amsgrad=amsgrad)
super(Adam, self).__init__(params, defaults)
@@ -46,6 +48,7 @@ class Adam(Optimizer):
for group in self.param_groups:
group.setdefault('amsgrad', False)
+ @torch.no_grad()
def step(self, closure=None):
"""Performs a single optimization step.
@@ -55,13 +58,14 @@ class Adam(Optimizer):
"""
loss = None
if closure is not None:
- loss = closure()
+ with torch.enable_grad():
+ loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
- grad = p.grad.data
+ grad = p.grad
if grad.is_sparse:
raise RuntimeError('Adam does not support sparse gradients, please consider SparseAdam instead')
amsgrad = group['amsgrad']
@@ -72,12 +76,12 @@ class Adam(Optimizer):
if len(state) == 0:
state['step'] = 0
# Exponential moving average of gradient values
- state['exp_avg'] = torch.zeros_like(p.data)
+ state['exp_avg'] = torch.zeros_like(p, memory_format=torch.preserve_format)
# Exponential moving average of squared gradient values
- state['exp_avg_sq'] = torch.zeros_like(p.data)
+ state['exp_avg_sq'] = torch.zeros_like(p, memory_format=torch.preserve_format)
if amsgrad:
# Maintains max of all exp. moving avg. of sq. grad. values
- state['max_exp_avg_sq'] = torch.zeros_like(p.data)
+ state['max_exp_avg_sq'] = torch.zeros_like(p, memory_format=torch.preserve_format)
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
if amsgrad:
@@ -85,25 +89,25 @@ class Adam(Optimizer):
beta1, beta2 = group['betas']
state['step'] += 1
+ bias_correction1 = 1 - beta1 ** state['step']
+ bias_correction2 = 1 - beta2 ** state['step']
if group['weight_decay'] != 0:
- grad.add_(group['weight_decay'], p.data)
+ grad = grad.add(p, alpha=group['weight_decay'])
# Decay the first and second moment running average coefficient
- exp_avg.mul_(beta1).add_(1 - beta1, grad)
- exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
+ exp_avg.mul_(beta1).add_(grad, alpha=1 - beta1)
+ exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1 - beta2)
if amsgrad:
# Maintains the maximum of all 2nd moment running avg. till now
torch.max(max_exp_avg_sq, exp_avg_sq, out=max_exp_avg_sq)
# Use the max. for normalizing running avg. of gradient
- denom = max_exp_avg_sq.sqrt().add_(group['eps'])
+ denom = (max_exp_avg_sq.sqrt() / math.sqrt(bias_correction2)).add_(group['eps'])
else:
- denom = exp_avg_sq.sqrt().add_(group['eps'])
+ denom = (exp_avg_sq.sqrt() / math.sqrt(bias_correction2)).add_(group['eps'])
- bias_correction1 = 1 - beta1 ** state['step']
- bias_correction2 = 1 - beta2 ** state['step']
- step_size = group['lr'] * math.sqrt(bias_correction2) / bias_correction1
+ step_size = group['lr'] / bias_correction1
- p.data.addcdiv_(-step_size, exp_avg, denom)
+ p.addcdiv_(exp_avg, denom, value=-step_size)
return loss
As a test copy-paste the v1.2.0 adam.py file and train your model with it to see if these changes are indeed causing the issue.