Hi,
I’m trying to train a three layer fully connected net to approximate a simple sine function. It seems the net is having a hard time to learn the parameters. It converges around the center, but not at the edges. It also takes much more cycles than claims I saw in academic papers.
The paper is called: “The Convergence Rate of Neural Networks for Learned Functions of Different Frequencies”. In one of the examples it is shown that after 50 epochs you get a pretty clear sine wave.
No, the paper did not include these details. However, this is such a simple example, and my code produce weird results converging only in the center. Regardless of the paper, it seems like I’m doing something wrong.
Two things that jump out, try to move optimizer.zero_grad() in the beginning of the loop and move model.train() outside of the training loop. Also, add another dimension to your data and see if it helps at all. Finally the 3 lines after # variables for plotting results are they necessary? What if you plot y_hat at the end of training against y over x_train_tensor.
I was playing around with your code, and using exactly your parameters, but including momentum (0.9) and weight_decay(1e-5), you get a better fit. However, it still takes 1000’s of epochs to get there, way more than the 50 mentioned in the paper. The best looking fit I found was using,
4 layers of 512 neurons each
max_epochs = 2000
lr = 1e-2
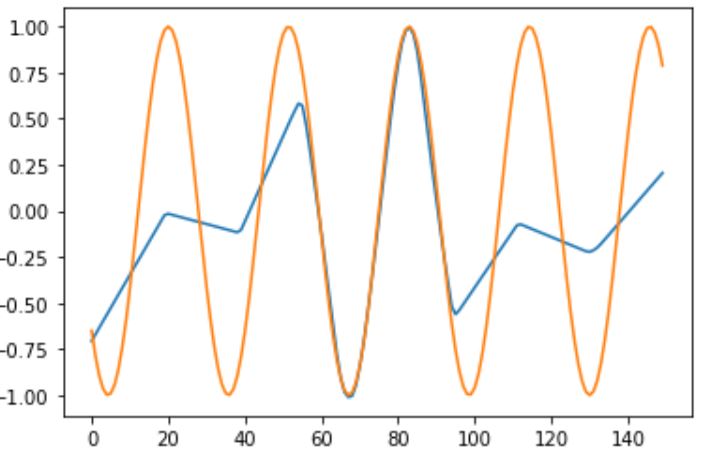
By 800 epochs, you have almost a perfect fit. However, the loss seems a bit iffy. I will still look into it. I’m curious as to how they managed to get that result in 50 epochs because that is blowing my mind.
Edit: Wanted to mention that this worked only for a frequency of 2. When changed to 4, it cannot estimate the full wave.
If that the case then as the legend says the network is fitting a superposition of two sine waves with frequencies 4 and 14 and not just one. Additionally, at epoch 50 they claim the network has learned the lower freq component and only at epoch 22452 fits completely the superposition of sine functions
Tried that as well. I can get the function to fit, but it doesn’t work as described in the paper. It starts mirroring the function in the middle, and then gradually fans out.
The data_range parameter also plays a role. If I want to fit it to just one oscillation, I can get it done within 100 epochs. I’m wondering if that is enough as you can simply concatenate (don’t know if that’s the right word) it multiple times.
I suppose that means you tried on two superimposed sine waves?, that’s important cause it provides more structure for the network to fit. But if it didn’t work then that’s sketchy, are you replicating the same net architecture and params as in the paper, discliamer haven’t read the full paper in detail so I dunno what net they used to produce Figure 2.
I don’t suppose that would work in reality, what I mean is usually we don’t know the underlying structure of data that’s one of the main reasons we use these nets. We usually hope to approximate the data as close as possible but if we know in advance our problem then we could use that knowledge.
Yup, that’s on the superposition. I skimmed through the paper, but wasn’t able to find any architecture or params related to the network used in producing Figure. 2.
That does make sense. Even playing around with the superimposed signal, increasing the number of data points, increases the time it needed to learn the entire scope of the function.
The paper shows that networks has the tendency to converge to lower frequencies faster than to higher frequencies, so, for the purpose of this discussion, I think you can disregard the higher frequency. and you can see a clear shape of a sine wave after 50 epochs.
The thing is, there is no mention of the architecture used in getting that figure. Upon trying it out myself, the learning process doesn’t work as described in the paper. As mentioned in one of my previous replies, you can get a sine wave within 100 epochs using the architecture I mentioned above, but that is only for a single oscillation.
After reading your comment I was thinking what would happen if you were to blow up the network? You could try depth, width and then both. In other words try to heavily overparameterise the network and see what happens?
The thing is, you should be able to approximate any function using a two layered net. This is the main reason this example is interesting to me. @pchandrasekaran has already shown that adding layers and epoches will get a convergence of more cycles…
Not going to lie, this has piqued my interest as well. 2 layers does work, but it can predict a maximum of 2 oscillations before it fails, and that too only at around 800 epochs. I will work on this during the weekend and will mention if I figure out anything. My main gripe is that the learning for the superimposed function isn’t taking place the way it’s been described.
@kirk86 Exploding it yields the same results, just more time to get there, but at literally the same epoch, lol.
There are several approximation theorems and plenty of subtleties and nuances when transitioning from theory to practice. E.g. those theorems talk about continuous functions and almost surely when the number of samples goes to infinity. Computers are by design discrete machines and just by thinking the differences between continuous and discrete optimisation seems like magic (at least to me) that we are able to get away with it and having these models working in the first place.