Im training a neural network of two parts, end-to-end. The first part consist in a Message passing Graph neural net that makes embeddings of the nodes, and the second part is a MLP that predicts similarity for a pair of nodes. Im training this by K-fold cross-validation with k=5, with random state fixed. The model was performing very well in a little dataset. When i scale the model with a 6x dataset, the model doesn’t train in 4 of the 5 folds.
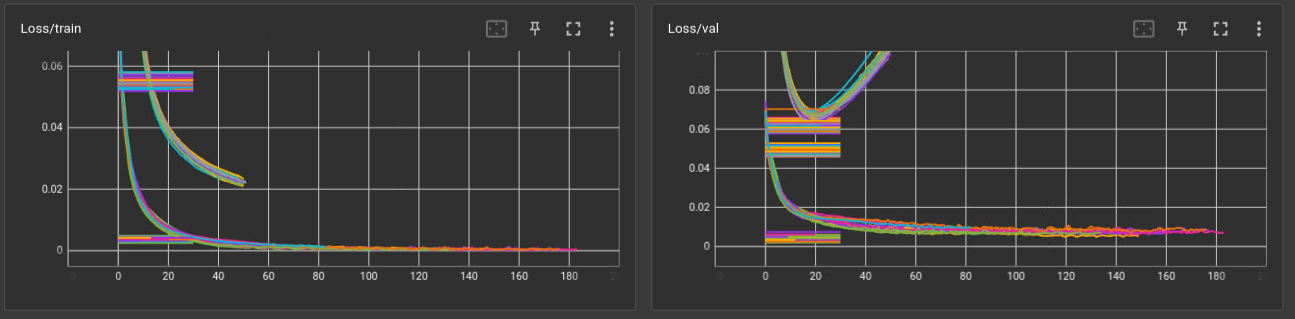
Here we can see the Training loss (left) and val loss (right) throughout the epochs. Every line is a fold. The differences of the magnitudes is because im training the model with 2 different loss functions. The thing here is that in all cases the first fold train properly an then the others don’t evolve at all.
Thing i try: Changin the activation from ReLU to SELU to avoid dying ReLU. Initialize all the weights with He (Kaiming). -->Nothing changes.
Could you give me a clue where to attack the problem?