I am trying to train a simple neural network for regression problem. Here X_train, y_train, X_valid, y_vlid are my X/y numpy arrays for training/validation. After running the training, my training and validation loss are empty (NaN). Here is my
model, criterion and training function, is there a problem with my function?
How does the loss curve look like?
Is it decreasing at all or just rising?
In the latter case, could you try to lower the learning rate even more?
Also, what kind of data are you using?
What is the min, max, mean, std of your data?
Normalizing might help, if you are dealing with a large range of values.
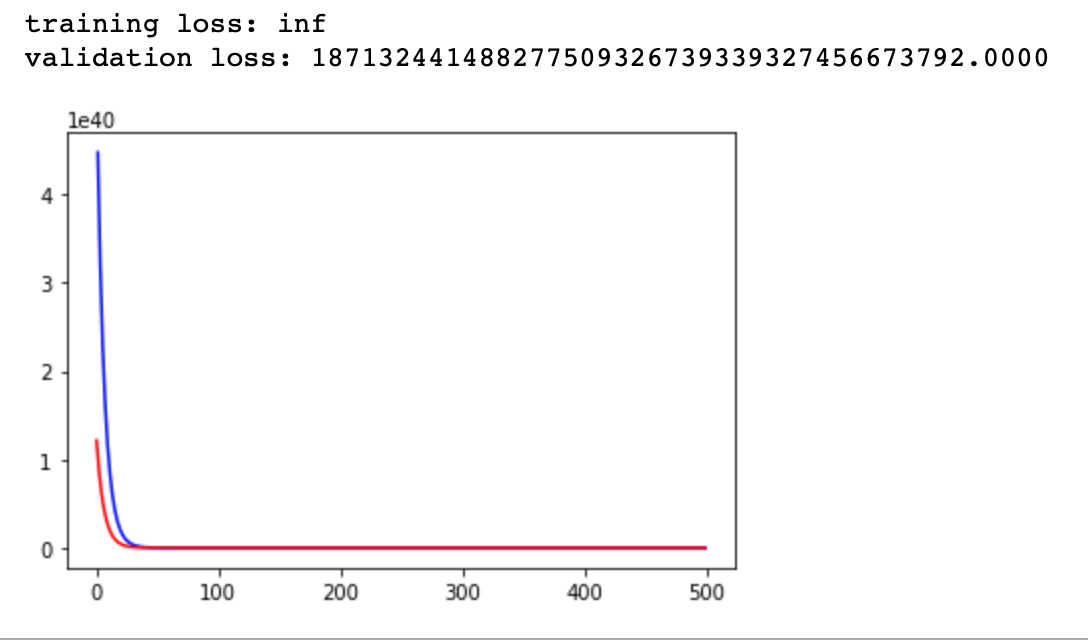
The losses I reported previously was with learning rate of 0.001 and epochs=500. If i increase the epochs to 2000, the loss just go up to inf. If i decrease the learning rate to 0.0001 and keep the epoch at 500, the loss are still large . here is the graph:
My y range is 0-4 and so i did not normalize it. I then tried classification (with 5 classes); the validation accuracy is now 0.58 (with normalization) … I was wondering if there is any other things i can try to minimize/improve the loss/accuracy?
I tried learning rate scheduler with cosine annealing and tried different learning rate but the improvement is insignificant.
Are you sure you are passing the normalized data to your model?
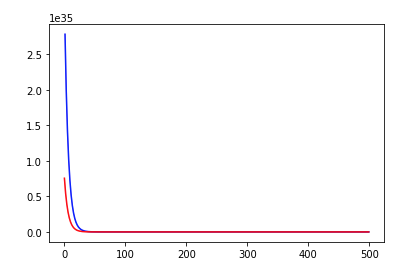
If the new mean values is approx. 0 and the target is in range [0, 4], the loss shouldn’t be at >1e35.
Could you print a sample output of the first data batch you are feeding to the model?
No, the loss should decrease. Try to lower the learning rate until you observe a decreasing loss.
Also, make sure you are zeroing the gradients after each update step.