Hi. I’m studying pytorch and RNN.
I can configure simple integer seqeunce prediction model wth embedding.
So, I’m trying to make a model that predict stock price.
This is my idea and model configuration code.
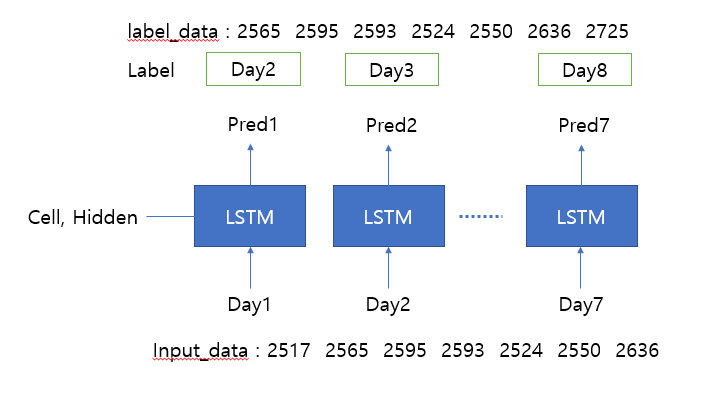
The results shown are completely different from the estimates.

And this is my code.
import numpy as np
import torch
import torch.nn as nn
from torch.autograd import Variable
from custom_data_loader import TimeSeries
from torch.utils.data import Dataset, DataLoader
import time, math
class myRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layer):
super(myRNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layer = num_layer
#embedded = nn.Embedding(input_size, hidden_size)
self.lstm1 = nn.LSTM(input_size, hidden_size, num_layer)
def forward(self, input, hidden, cell):
#embedded_input = self.embedded(input)
output, hidden = self.lstm1(input, (hidden, cell))
#deembedded_output = output.view(-1, hidden_size) @ self.embedded.weight.transpose(0,1)
return output,(hidden, cell)
def init_hidden(self):
hidden = Variable(torch.zeros(num_layer, batch_size, hidden_size))
return hidden
if __name__ == '__main__':
seq_len = 7
input_size = 1
hidden_size = 12000
num_layer = 1
batch_size = 1
#
rnn = myRNN(input_size, hidden_size, num_layer)
#loss, optimizer
optimizer = torch.optim.Adam(rnn.parameters(), lr = 0.0001)
data_from = TimeSeries(seq_len)
train_loader = DataLoader(dataset= data_from,
batch_size = batch_size,
shuffle = True,
num_workers = 2)
for epoch in range(300):
for i , data in enumerate(train_loader,0):
inputs, labels = data
inputs = Variable(inputs.view(-1, batch_size, input_size))
labels = Variable(labels.view(-1, batch_size, input_size))
print('Input/Label Size :::: ', inputs.size(), labels.size())
state = Variable(torch.zeros(num_layer,batch_size,hidden_size))
cell = Variable(torch.zeros(num_layer,batch_size,hidden_size))
out, state = rnn(inputs, state, cell)
optimizer.zero_grad()
out = out.view(-1, hidden_size)
labels = labels.view(-1).long()
print('Output/Label Size :::: ', out.size(), labels.size())
loss = nn.CrossEntropyLoss()
err = loss(out, labels)
err.backward()
optimizer.step()
print('[input]', inputs.view(1,-1))
print('[target]', labels.view(1,-1))
print('[prediction] ', out.data.max(1)[1])
print('-------done')
import torch
import numpy as np
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
from numpy import genfromtxt
import csv
class TimeSeries(Dataset):
def __init__(self, seq_len):
self.seq_len = seq_len
self.data = []
f = open('C:/Users/asdfw/Desktop/ICC_Example/data/BTCUSD.csv', 'r')
csvReader = csv.reader(f)
for i in csvReader:
if i[1] != 'High':
self.data.append(i[1])
f.close()
self.data = np.asarray(self.data, dtype=int)
self.len = self.data.shape[0]
self.x_data = torch.from_numpy(self.data[:-1])
self.y_data = torch.from_numpy(self.data[1:])
self.input = torch.FloatTensor(self.len-seq_len,seq_len)
self.label = torch.FloatTensor(self.len-seq_len,seq_len)
for i in range(self.len-seq_len):
for j in range(seq_len):
self.input[i][j] = self.x_data[i+j]
for i in range(self.len-seq_len):
for j in range(seq_len):
self.label[i][j] = self.y_data[i+j]
print(self.input.size())
print(self.label.size())
self.len = self.input.shape[0]
def __getitem__(self, item):
return self.input[item], self.label[item]
def __len__(self):
return self.len
So, can i get a appropriate source code that works well ?