New announcement from UW and Amazon:
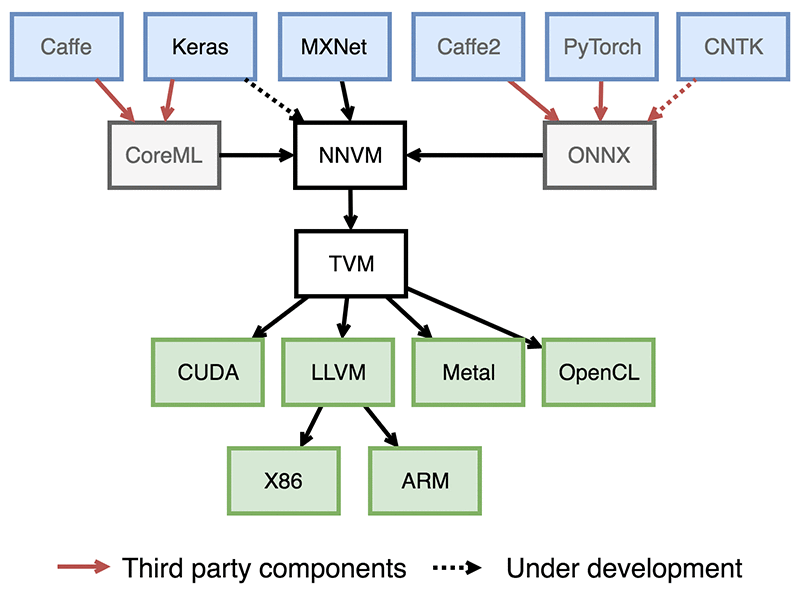
It feels like over-engineering to me and I am skeptical about this for several reasons:
-
2.2x perf improvements with LLVM on CPU vs hand-tuned OpenBLAS and NNPACK? Even D Mir GLAS only claims MKL-like performance
-
How does the compiler deal with dynamic graph/variable sized input.
It seems like the framework is for production but if not:
-
How often do we need to compile? That was already a pain point in Theano.
-
What’s the build toolchain like? Bazel for Tensorflow is already a huge pain (especially in containers) and this seems even more complicated.
-
I see Jenkins/Travis tests but what is the coverage for ONNX?
(Note that i’m asking OP to answer, I’m just raising concerns)
Edit: Would be interested to know what did they choose as default layout: CHWN (Neon), NCHW (Caffe / Torch), NHWC (Tensorflow) as it has implications in convolutions performance and algorithm choice.
Yeah I agree with your concerns @mratsim : 5 layers of compilers would be a nightmare to debug. This stack can be useful in deploying a really well-tested model, but will be hard to use it for research or product development setting.
How does the compiler deal with dynamic graph/variable sized input.
ONNX translates dynamic graphs to static based on most-traversed path, so rest of the tool chain would work off of the static graph.
Source: Log into Facebook