Hello!
When using
next(iter(train_dataloader))
I have two issues:
- The dataloader doesn’t stop.
TEST_SET has length of 101. I can iterate 1000 times and more …
Shouldn’t there be astopIteration?
– My CustomDataset contains a __len__ which (if I print it out within the __getitem__ seems to work).
- Output is redundant
I saved the DataLoader-Output to a CSV-File
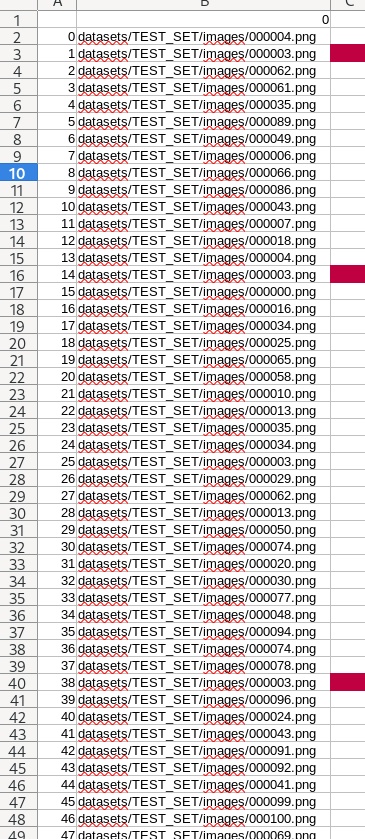
Quite a lot of Images are more than double.
0000003.png is not the only file.
This shouldn’t be the case, right?
What could be the reason therefore?
I am using the torchvision.datasets.kitti — Torchvision main documentation Dataset; just a bit adjusted to my own needings.
################
train_dataloader = DataLoader(dataset=train_data,
collate_fn= None,
batch_size=1, # how many samples per batch?
num_workers=1, # how many subprocesses to use for data loading? (higher = more)
pin_memory=True,
shuffle=True) # shuffle the data?
This is how I have tested my DataLoader:
image_list = []
for count in range(0, 1001):
a = next(iter(train_dataloader))
image_list.append(a)
if count % 100 == 0:
print(f"{count} of 1000")
print(f"Last index is: {count}")
liste = pd.DataFrame(image_list)
liste.to_csv('myDataTest/image_list.csv')