Hello.
I’m trying to train a model on multiGPU using nn.DataParallel and the program gets stuck. (in the sense I can’t even ctrl+c to stop it). My system has 3x A100 GPUs. However, the same code works on a multi-GPU system using nn.DataParallel on system with V100 GPUs. How can I debug what’s going wrong?
I have installed pytorch and cudatoolkit using anaconda. Both are in its latest version (as of writing this post). Nvidia driver version is 465 and Cuda version is 11.0.
Output of $ nvidia-smi topo -m
GPU0 GPU1 GPU2 CPU Affinity NUMA Affinity
GPU0 X SYS SYS 0-15,32-47 0
GPU1 SYS X NODE 16-31,48-63 1
GPU2 SYS NODE X 16-31,48-63 1
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
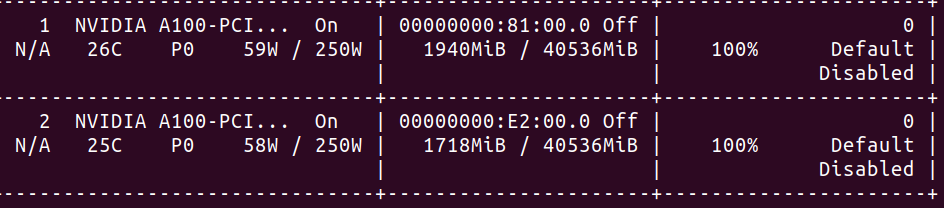
Output of $nvidia-smi
$ nvidia-smi
Wed Jun 30 05:51:19 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 465.19.01 Driver Version: 465.19.01 CUDA Version: 11.3 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-PCI... On | 00000000:21:00.0 Off | 0 |
| N/A 21C P0 33W / 250W | 0MiB / 40536MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A100-PCI... On | 00000000:81:00.0 Off | 0 |
| N/A 22C P0 35W / 250W | 11615MiB / 40536MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA A100-PCI... On | 00000000:E2:00.0 Off | 0 |
| N/A 21C P0 32W / 250W | 0MiB / 40536MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
Output of $ python -c "import torch;print(torch.__version__);print(torch.cuda.is_available())"
1.8.1+cu111
True
Thank you