What is the error that you get then? Because the error you report above is about the assert.
When I call loss, _, _ = self.model(data_pack) This error occurs. So I test all the inputs and parameters they are OK. So I’m confused why this assert failed.
I upload the error snip
This Assertion Error occurs before I add these 2 assert.
And After adding these assert, this assertion error occurs in the SAME line! Not the assert I add… I don’t know why.
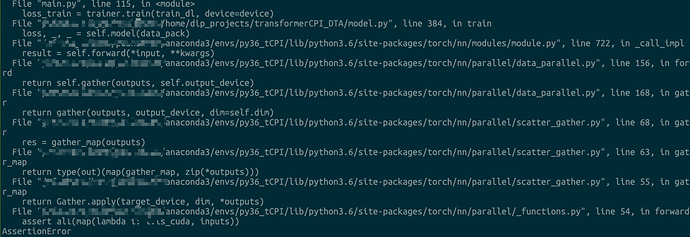
From the stack trace it looks like the problem is with the outputs no?
Maybe your forward returns Tensors that are not on the right device?
Yes. Sorry, in this line I put tensor to cpu before gather.
return torch.unsqueeze(loss, 0), predicted_interaction.cpu().detach().view(-1, 1), correct_interaction.cpu().detach().view(-1, 1)
Thank you so much!!! I finally make the code work with nn.DataParallel!
How can I specify the behavior of DataParallel dividing the batch into parts?
Since my data preprocessing contains padding operations, I can’t make the batch size very large.
If the batch size grows linearly, the GPU memory my data uses grows much faster than linear since the padding use the max_len of some dim.
How can I feed different size of tensor to different GPUs?
BTW, you solved many of my problems. Is there anyway I can sponsor sth to help you?
Hi,
I’m afraid DataParallel is fairly simple and just splits the given Tensors along the first dimension. Also the Dataloader only loads batch of data of same size usually as they are concatenated into a single Tensor.
You can try to delay the propocessing inside the DataParallel but then you will need to split the datas by hand if they don’t all have the same size.
BTW, you solved many of my problems. Is there anyway I can sponsor sth to help you?
No worries, happy to help ![]()
I have a stupid question. If I’m using Iterable DataSet why should I use num_workers>1 in my DataLoader? I only need the next batch for training right? Or it has nothing to do with the dataset?
If you have transforms or preprocessing, Using num_workers>1 will allow it to happen asynchronously in a different process. But you don’t have to no.
You mean num_workers>0 or num_workers>1? In my opinion, num_workers=0 means loading data in main process, but num_workers=1 will load data in a single child process, which will already be asynchronous right? So why should I set num_workers>1 ? Or may be the program is too fast? Thank you very much!
Ho sorry I read your question too quickly, I though it was >0.
Indeed >1 might not have a huge benefit but in some case, the loading from disk + preprocessing is so slow that it is actually slower than a forward/backward/step. And so a single worker, even working asynchronously, is not able to feed your training fast enough.
This is especially true if you have a relatively small network, have a spinning drive or have a custom preprocessing that is slow.
Congratulations for pytorch 1.7.0 release!!
I have another question. Say my trained model is f_\theta(x), and I want to solve the nonlinear equation f_\theta(x)=c, c is a constant. How can I fix the weights \theta in the original model and treat my input x as new parameters and optimize x for that nonlinear equation?
I means I treat the trained model as a general fixed function, and want to solve nonlinear equation f(x)=c using pytorch.
Thank you very much!!
Hi,
You can stop requirering gradients for all the parameters in the net by doing net.requires_grad_(False).
The you need to make sure your input requires grad x.requires_grad=True (before doing the forward).
And then you can either give [x,] to an optimizer and do .backward() your loss as you would do for a regular training.
1 Like