I have been using in my machine a network, that is nothing really special. I wanted to do it faster so I started using google cloud. But I notice something weird that my machine with a GTX 1050 ti was faster than a V100 GPU. This didn’t add up so I checked the usage and it seems that even though I put some stress by creating a big network and passing a lot of data to it the gpu by using a simple .cuda() in both the model and the data: there wasn’t ussage shown in nvidia-smi command as shown in the image
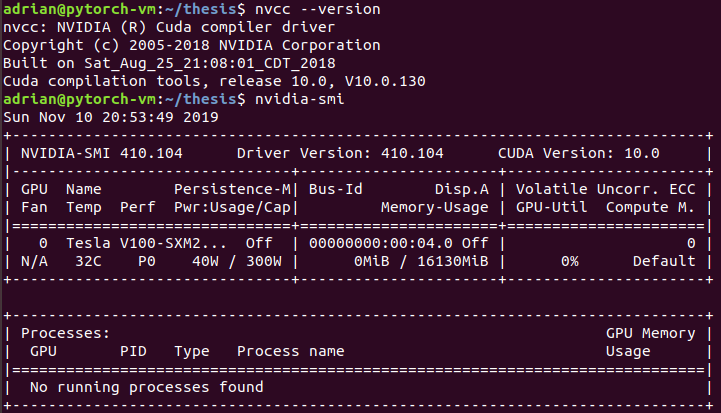
you can check my code here:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("The device is:",device,torch.cuda.get_device_name(0),"and how many are they",torch.cuda.device_count())
# # We load the training data
Samples , Ocupancy, num_samples, Samples_per_slice = common.load_samples(args.samples_filename)
Samples = Samples * args.scaling_todo
print(Samples_per_slice)
# Divide into Slices
Organize_Positions,Orginezed_Ocupancy, batch_size = common.organize_sample_data(Samples,Ocupancy,num_samples,Samples_per_slice,args.num_batches)
phi = common.MLP(3, 1).cuda()
x_test = torch.from_numpy(Organize_Positions.astype(np.float32)).cuda()
y_test = torch.from_numpy(Orginezed_Ocupancy.astype(np.float32)).cuda()
all_data = common.CustomDataset(x_test, y_test)
#Dive into Slices the data
Slice_data = DataLoader(dataset=all_data, batch_size = batch_size, shuffle=False) # only take batch_size = n/b TODO Don't shuffle
#Chunky_data = DataLoader(dataset=Slice_data, batch_size = chunch_size, shuffle=False)
criterion = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(phi.parameters(), lr = 0.0001)
epoch = args.num_epochs
fit_start_time = time.time()
phi.train()
for epoch in range(epoch):
curr_epoch_loss = 0
batch = 0
for x_batch, y_batch in Slice_data:
optimizer.zero_grad()
x_train = x_batch
#print(x_train,batch_size)
y_train = y_batch
y_pred = phi(x_train)
#print(y_pred,x_train)
loss = criterion(y_pred.squeeze(), y_train.squeeze())
curr_epoch_loss += loss
print('Batch {}: train loss: {}'.format(batch, loss.item())) # Backward pass
loss.backward()
optimizer.step() # Optimizes only phi parameters
batch+=1
print('Epoch {}: train loss: {}'.format(epoch, loss.item()))
fit_end_time = time.time()
print("Total time = %f" % (fit_end_time - fit_start_time))
# Save Model
torch.save({'state_dict': phi.state_dict()}, args.model_filename)
and the model here:
class MLP(nn.Module):
def __init__(self, in_dim: int, out_dim: int):
super().__init__()
self.in_dim = in_dim
self.out_dim = out_dim
self.fc1 = nn.Linear(in_dim, 128)
self.fc1_bn = nn.BatchNorm1d(128)
self.fc2 = nn.Linear(128, 256)
self.fc2_bn = nn.BatchNorm1d(256)
self.fc3 = nn.Linear(256, 512)
self.fc3_bn = nn.BatchNorm1d(512)
self.fc4 = nn.Linear(512, 512)
self.fc4_bn = nn.BatchNorm1d(512)
self.fc5 = nn.Linear(512, out_dim,bias=False)
self.relu = nn.LeakyReLU()
def forward(self, x):
x = self.relu(self.fc1_bn(self.fc1(x)))
x = self.relu(self.fc2_bn(self.fc2(x)))# leaky
x = self.relu(self.fc3_bn(self.fc3(x)))
x = self.relu(self.fc4_bn(self.fc4(x)))
x = self.fc5(x)
return x
class CustomDataset(Dataset):
def __init__(self, x_tensor, y_tensor):
self.x = x_tensor
self.y = y_tensor
def __getitem__(self, index):
return (self.x[index], self.y[index])
def __len__(self):
return len(self.x)