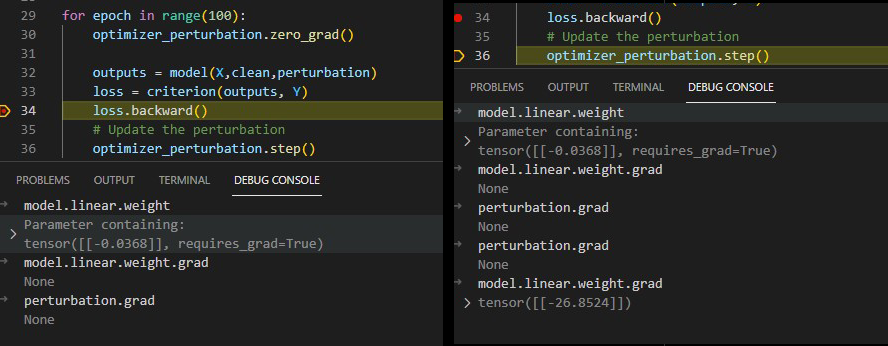
When I was trying to add a perturbation to a model and optimize the perturbation itself but not the model parameters. I did like the following, which is very simple:
import torch
import torch.nn as nn
import torch.optim as optim
# Define a simple model
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x, perturbation, clean):
self.linear.weight.data = perturbation + clean
return self.linear(x)
# Generate clean dataset
X = torch.tensor([[1.0], [2.0], [3.0], [4.0]], dtype=torch.float32)
Y = 2 * X
# Create the model
model = SimpleModel()
# Define perturbation as a separate parameter
perturbation = torch.tensor(0.1, requires_grad=True)
clean = model.linear.weight.data
# Train the model and optimize the perturbation
criterion = nn.MSELoss()
optimizer_perturbation = optim.SGD([perturbation], lr=0.01) # Optimize the perturbation
for epoch in range(100):
optimizer_perturbation.zero_grad()
outputs = model(X,clean,perturbation)
loss = criterion(outputs, Y)
loss.backward()
# Update the perturbation
optimizer_perturbation.step()
However, the gradient of perturbation was still None after executing loss.backward(). I cannot figure out why. What caused this problem and what should I do to realize the result I needed?
The short answer is that the (public-facing) use of .data is deprecated and
can lead to errors.
More generally, pytorch really doesn’t like to let you modify Parameters
(such as self.linear.weight) while they are being tracked by autograd.
To fix this issue for the use case you posted, use the functional version of linear():
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.weight = torch.randn (1, 1) # not a Parameter
self.bias = torch.randn (1) # not a Parameter
def forward(self, x, perturbation, clean):
return torch.nn.functional.linear (x, self.weight + perturbation + clean, self.bias)
If the perturbation you pass into SimpleModel has requires_grad = True,
then you will be able to backpropagate through the call to SimpleModel and
obtain gradients for perturbation.
As an aside, please don’t post screenshots of textual information as doing so
breaks accessibility, searchability, and copy-paste.