Hi, please help me
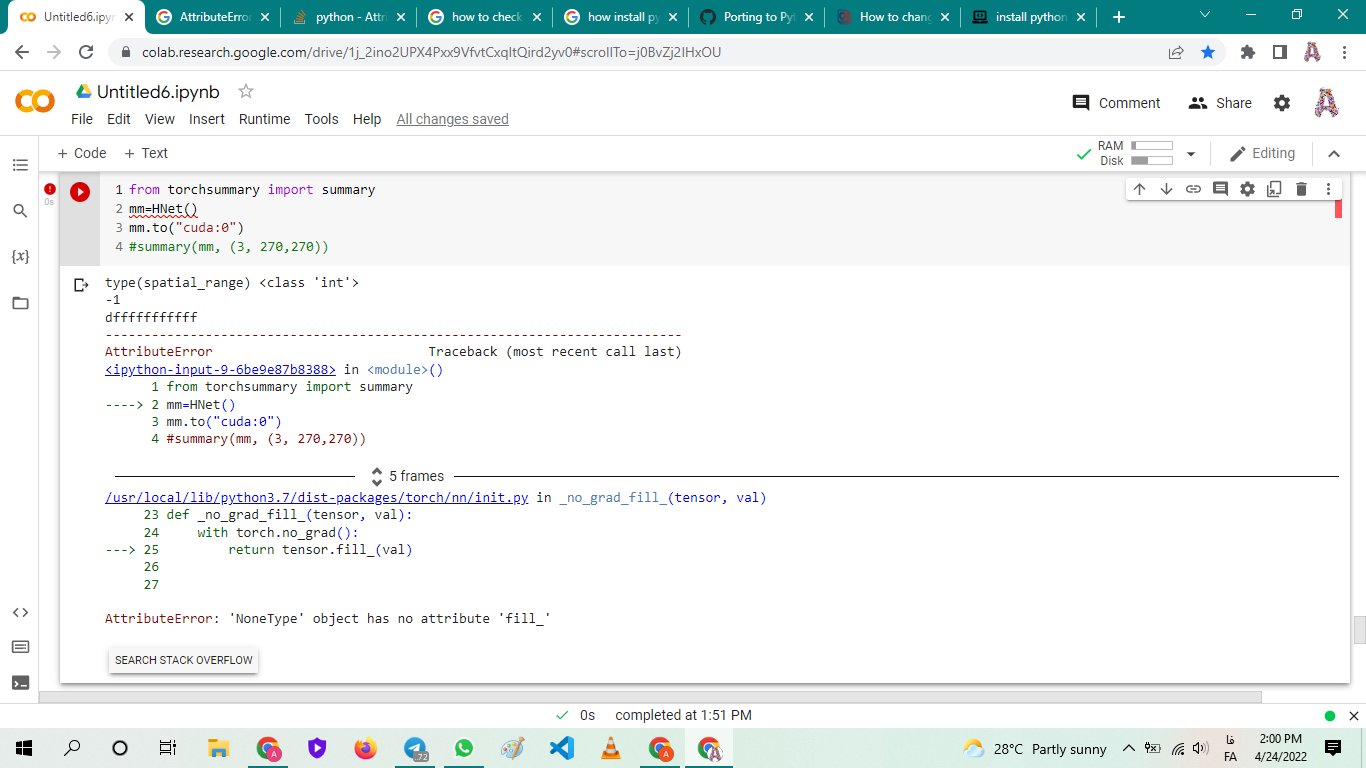
Could you post a minimal, executable code snippet reproducing the issue, please?
In particular, the model definition would be needed as it seems that some internal parameter initialization fails.
class GeneralizedAttention(nn.Module):
def __init__(self,
in_dim,
spatial_range=-1,
num_heads=9,
position_embedding_dim=-1,
position_magnitude=1,
kv_stride=2,
q_stride=1,
attention_type='1111'):
super(GeneralizedAttention, self).__init__()
# hard range means local range for non-local operation
self.position_embedding_dim = (
position_embedding_dim if position_embedding_dim > 0 else in_dim)
self.position_magnitude = position_magnitude
self.num_heads = num_heads
self.channel_in = in_dim
self.spatial_range = spatial_range
self.kv_stride = kv_stride
self.q_stride = q_stride
self.attention_type = [bool(int(_)) for _ in attention_type]
self.qk_embed_dim = in_dim // num_heads
out_c = self.qk_embed_dim * num_heads
if self.attention_type[0] or self.attention_type[1]:
self.query_conv = nn.Conv2d(
in_channels=in_dim,
out_channels=out_c,
kernel_size=1,
bias=False)
self.query_conv.kaiming_init = True
if self.attention_type[0] or self.attention_type[2]:
self.key_conv = nn.Conv2d(
in_channels=in_dim,
out_channels=out_c,
kernel_size=1,
bias=False)
self.key_conv.kaiming_init = True
self.v_dim = in_dim // num_heads
self.value_conv = nn.Conv2d(
in_channels=in_dim,
out_channels=self.v_dim * num_heads,
kernel_size=1,
bias=False)
self.value_conv.kaiming_init = True
if self.attention_type[1] or self.attention_type[3]:
self.appr_geom_fc_x = nn.Linear(
self.position_embedding_dim // 2, out_c, bias=False)
self.appr_geom_fc_x.kaiming_init = True
self.appr_geom_fc_y = nn.Linear(
self.position_embedding_dim // 2, out_c, bias=False)
self.appr_geom_fc_y.kaiming_init = True
if self.attention_type[2]:
stdv = 1.0 / math.sqrt(self.qk_embed_dim * 2)
appr_bias_value = -2 * stdv * torch.rand(out_c) + stdv
self.appr_bias = nn.Parameter(appr_bias_value)
if self.attention_type[3]:
stdv = 1.0 / math.sqrt(self.qk_embed_dim * 2)
geom_bias_value = -2 * stdv * torch.rand(out_c) + stdv
self.geom_bias = nn.Parameter(geom_bias_value)
self.proj_conv = nn.Conv2d(
in_channels=self.v_dim * num_heads,
out_channels=in_dim,
kernel_size=1,
bias=True)
self.proj_conv.kaiming_init = True
self.gamma = nn.Parameter(torch.zeros(1))
if self.spatial_range >= 0:
# only works when non local is after 3*3 conv
if in_dim == 256:
max_len = 84
elif in_dim == 512:
max_len = 42
max_len_kv = int((max_len - 1.0) / self.kv_stride + 1)
local_constraint_map = np.ones(
(max_len, max_len, max_len_kv, max_len_kv), dtype=np.int)
for iy in range(max_len):
for ix in range(max_len):
local_constraint_map[
iy, ix,
max((iy - self.spatial_range) //
self.kv_stride, 0):min((iy + self.spatial_range +
1) // self.kv_stride +
1, max_len),
max((ix - self.spatial_range) //
self.kv_stride, 0):min((ix + self.spatial_range +
1) // self.kv_stride +
1, max_len)] = 0
self.local_constraint_map = nn.Parameter(
torch.from_numpy(local_constraint_map).byte(),
requires_grad=False)
if self.q_stride > 1:
self.q_downsample = nn.AvgPool2d(
kernel_size=1, stride=self.q_stride)
else:
self.q_downsample = None
if self.kv_stride > 1:
self.kv_downsample = nn.AvgPool2d(
kernel_size=1, stride=self.kv_stride)
else:
self.kv_downsample = None
self.init_weights()
def get_position_embedding(self,
h,
w,
h_kv,
w_kv,
q_stride,
kv_stride,
device,
feat_dim,
wave_length=1000):
h_idxs = torch.linspace(0, h - 1, h).cuda(device)
h_idxs = h_idxs.view((h, 1)) * q_stride
w_idxs = torch.linspace(0, w - 1, w).cuda(device)
w_idxs = w_idxs.view((w, 1)) * q_stride
h_kv_idxs = torch.linspace(0, h_kv - 1, h_kv).cuda(device)
h_kv_idxs = h_kv_idxs.view((h_kv, 1)) * kv_stride
w_kv_idxs = torch.linspace(0, w_kv - 1, w_kv).cuda(device)
w_kv_idxs = w_kv_idxs.view((w_kv, 1)) * kv_stride
# (h, h_kv, 1)
h_diff = h_idxs.unsqueeze(1) - h_kv_idxs.unsqueeze(0)
h_diff *= self.position_magnitude
# (w, w_kv, 1)
w_diff = w_idxs.unsqueeze(1) - w_kv_idxs.unsqueeze(0)
w_diff *= self.position_magnitude
feat_range = torch.arange(0, feat_dim / 4).cuda(device)
dim_mat = torch.Tensor([wave_length]).cuda(device)
dim_mat = dim_mat**((4. / feat_dim) * feat_range)
dim_mat = dim_mat.view((1, 1, -1))
embedding_x = torch.cat(
((w_diff / dim_mat).sin(), (w_diff / dim_mat).cos()), dim=2)
embedding_y = torch.cat(
((h_diff / dim_mat).sin(), (h_diff / dim_mat).cos()), dim=2)
return embedding_x, embedding_y
def forward(self, x_input):
num_heads = self.num_heads
# use empirical_attention
if self.q_downsample is not None:
x_q = self.q_downsample(x_input)
else:
x_q = x_input
n, _, h, w = x_q.shape
if self.kv_downsample is not None:
x_kv = self.kv_downsample(x_input)
else:
x_kv = x_input
_, _, h_kv, w_kv = x_kv.shape
if self.attention_type[0] or self.attention_type[1]:
proj_query = self.query_conv(x_q).view(
(n, num_heads, self.qk_embed_dim, h * w))
proj_query = proj_query.permute(0, 1, 3, 2)
if self.attention_type[0] or self.attention_type[2]:
proj_key = self.key_conv(x_kv).view(
(n, num_heads, self.qk_embed_dim, h_kv * w_kv))
if self.attention_type[1] or self.attention_type[3]:
position_embed_x, position_embed_y = self.get_position_embedding(
h, w, h_kv, w_kv, self.q_stride, self.kv_stride,
x_input.device, self.position_embedding_dim)
# (n, num_heads, w, w_kv, dim)
position_feat_x = self.appr_geom_fc_x(position_embed_x).\
view(1, w, w_kv, num_heads, self.qk_embed_dim).\
permute(0, 3, 1, 2, 4).\
repeat(n, 1, 1, 1, 1)
# (n, num_heads, h, h_kv, dim)
position_feat_y = self.appr_geom_fc_y(position_embed_y).\
view(1, h, h_kv, num_heads, self.qk_embed_dim).\
permute(0, 3, 1, 2, 4).\
repeat(n, 1, 1, 1, 1)
position_feat_x /= math.sqrt(2)
position_feat_y /= math.sqrt(2)
# accelerate for saliency only
if (np.sum(self.attention_type) == 1) and self.attention_type[2]:
appr_bias = self.appr_bias.\
view(1, num_heads, 1, self.qk_embed_dim).\
repeat(n, 1, 1, 1)
energy = torch.matmul(appr_bias, proj_key).\
view(n, num_heads, 1, h_kv * w_kv)
h = 1
w = 1
else:
# (n, num_heads, h*w, h_kv*w_kv), query before key, 540mb for
if not self.attention_type[0]:
energy = torch.zeros(
n,
num_heads,
h,
w,
h_kv,
w_kv,
dtype=x_input.dtype,
device=x_input.device)
# attention_type[0]: appr - appr
# attention_type[1]: appr - position
# attention_type[2]: bias - appr
# attention_type[3]: bias - position
if self.attention_type[0] or self.attention_type[2]:
if self.attention_type[0] and self.attention_type[2]:
appr_bias = self.appr_bias.\
view(1, num_heads, 1, self.qk_embed_dim)
energy = torch.matmul(proj_query + appr_bias, proj_key).\
view(n, num_heads, h, w, h_kv, w_kv)
elif self.attention_type[0]:
energy = torch.matmul(proj_query, proj_key).\
view(n, num_heads, h, w, h_kv, w_kv)
elif self.attention_type[2]:
appr_bias = self.appr_bias.\
view(1, num_heads, 1, self.qk_embed_dim).\
repeat(n, 1, 1, 1)
energy += torch.matmul(appr_bias, proj_key).\
view(n, num_heads, 1, 1, h_kv, w_kv)
if self.attention_type[1] or self.attention_type[3]:
if self.attention_type[1] and self.attention_type[3]:
geom_bias = self.geom_bias.\
view(1, num_heads, 1, self.qk_embed_dim)
proj_query_reshape = (proj_query + geom_bias).\
view(n, num_heads, h, w, self.qk_embed_dim)
energy_x = torch.matmul(
proj_query_reshape.permute(0, 1, 3, 2, 4),
position_feat_x.permute(0, 1, 2, 4, 3))
energy_x = energy_x.\
permute(0, 1, 3, 2, 4).unsqueeze(4)
energy_y = torch.matmul(
proj_query_reshape,
position_feat_y.permute(0, 1, 2, 4, 3))
energy_y = energy_y.unsqueeze(5)
energy += energy_x + energy_y
elif self.attention_type[1]:
proj_query_reshape = proj_query.\
view(n, num_heads, h, w, self.qk_embed_dim)
proj_query_reshape = proj_query_reshape.\
permute(0, 1, 3, 2, 4)
position_feat_x_reshape = position_feat_x.\
permute(0, 1, 2, 4, 3)
position_feat_y_reshape = position_feat_y.\
permute(0, 1, 2, 4, 3)
energy_x = torch.matmul(proj_query_reshape,
position_feat_x_reshape)
energy_x = energy_x.permute(0, 1, 3, 2, 4).unsqueeze(4)
energy_y = torch.matmul(proj_query_reshape,
position_feat_y_reshape)
energy_y = energy_y.unsqueeze(5)
energy += energy_x + energy_y
elif self.attention_type[3]:
geom_bias = self.geom_bias.\
view(1, num_heads, self.qk_embed_dim, 1).\
repeat(n, 1, 1, 1)
position_feat_x_reshape = position_feat_x.\
view(n, num_heads, w*w_kv, self.qk_embed_dim)
position_feat_y_reshape = position_feat_y.\
view(n, num_heads, h * h_kv, self.qk_embed_dim)
energy_x = torch.matmul(position_feat_x_reshape, geom_bias)
energy_x = energy_x.view(n, num_heads, 1, w, 1, w_kv)
energy_y = torch.matmul(position_feat_y_reshape, geom_bias)
energy_y = energy_y.view(n, num_heads, h, 1, h_kv, 1)
energy += energy_x + energy_y
energy = energy.view(n, num_heads, h * w, h_kv * w_kv)
if self.spatial_range >= 0:
cur_local_constraint_map = \
self.local_constraint_map[:h, :w, :h_kv, :w_kv].\
contiguous().\
view(1, 1, h*w, h_kv*w_kv)
energy = energy.masked_fill_(cur_local_constraint_map,
float('-inf'))
attention = F.softmax(energy, 3)
proj_value = self.value_conv(x_kv)
proj_value_reshape = proj_value.\
view((n, num_heads, self.v_dim, h_kv * w_kv)).\
permute(0, 1, 3, 2)
out = torch.matmul(attention, proj_value_reshape).\
permute(0, 1, 3, 2).\
contiguous().\
view(n, self.v_dim * self.num_heads, h, w)
out = self.proj_conv(out)
out = self.gamma * out + x_input
return out
def init_weights(self):
for m in self.modules():
if hasattr(m, 'kaiming_init') and m.kaiming_init:
kaiming_init(
m,
mode='fan_in',
nonlinearity='leaky_relu',
bias=0,
distribution='uniform',
)def kaiming_init(module,
mode=‘fan_in’,
nonlinearity=‘leaky_relu’,
bias=0,
distribution=‘uniform’):
assert distribution in [‘uniform’, ‘normal’]
if distribution == ‘uniform’:
nn.init.kaiming_uniform_(
module.weight, mode=mode, nonlinearity=nonlinearity)
else:
nn.init.kaiming_normal_(
module.weight, mode=mode, nonlinearity=nonlinearity)
if hasattr(module, ‘bias’):
nn.init.constant_(module.bias, bias)
You are setting the bias to None in a few layers, but expect this parameter to be available in kaiming_init:
if hasattr(module, 'bias'):
nn.init.constant_(module.bias, bias)
Make sure to check, if this parameter is available before using it.
Also, you can post code snippets by wrapping them into three backticks ```, which makes debugging easier.
1 Like
Hello, Thank you so much