I built a training model where two datasets would be trained. Unfortunately, there is an error that implies that there is somewhat an issue with the parameter of the main training function.
Here is the error that shows up:
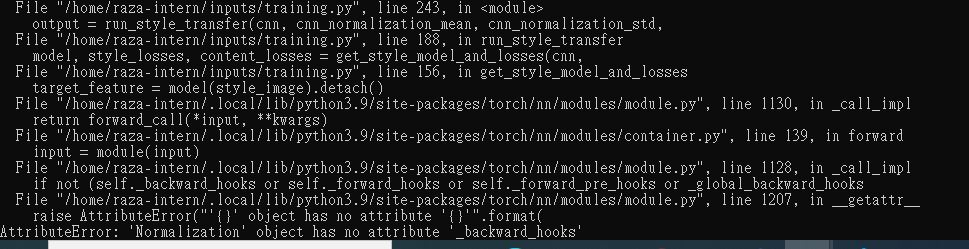
Here’s the dataloader part of code:
training_set_style = torchvision.datasets.ImageFolder('./style', transform=transform, target_transform=None)
training_set_content = torchvision.datasets.ImageFolder('./content', transform=transform, target_transform=None)
training_loader_style = torch.utils.data.DataLoader(training_set_style, batch_size=4, shuffle=True,num_workers=2)
training_loader_content = torch.utils.data.DataLoader(training_set_content, batch_size=4, shuffle=True,num_workers=2)
After this comes the loss function, which includes line 156.
Here’s the code for the loss function part:
def get_style_model_and_losses(cnn, cnn_normalization_mean, cnn_normalization_std,
training_loader_style, training_loader_content,
content_layers=content_layers_default,
style_layers=style_layers_default):
# normalization module
normalization = Normalization(cnn_normalization_mean, cnn_normalization_std)#.to(device)
# just in order to have an iterable access to or list of content/syle
# losses
content_losses = []
style_losses = []
# assuming that cnn is a nn.Sequential, so we make a new nn.Sequential
# to put in modules that are supposed to be activated sequentially
model = nn.Sequential(normalization)
i = 0 # increment every time we see a conv
for layer in cnn.children():
if isinstance(layer, nn.Conv2d):
i += 1
name = 'conv_{}'.format(i)
elif isinstance(layer, nn.ReLU):
name = 'relu_{}'.format(i)
# The in-place version doesn't play very nicely with the ContentLoss
# and StyleLoss we insert below. So we replace with out-of-place
# ones here.
layer = nn.ReLU(inplace=False)
elif isinstance(layer, nn.MaxPool2d):
name = 'pool_{}'.format(i)
elif isinstance(layer, nn.BatchNorm2d):
name = 'bn_{}'.format(i)
else:
raise RuntimeError('Unrecognized layer: {}'.format(layer.__class__.__name__))
model.add_module(name, layer)
if name in content_layers:
for batch in training_loader_content:
# add content loss:
content_image = batch[0].to(device)
print(content_image.shape)
target = model(content_image).detach()
content_loss = ContentLoss(target)
model.add_module("content_loss_{}".format(i), content_loss)
content_losses.append(content_loss)
if name in style_layers:
# add style loss:
for batch1 in training_loader_style:
style_image = batch1[0].to(device)
target_feature = model(style_image).detach()
style_loss = StyleLoss(target_feature)
model.add_module("style_loss_{}".format(i), style_loss)
style_losses.append(style_loss)
# now we trim off the layers after the last content and style losses
for i in range(len(model) - 1, -1, -1):
if isinstance(model[i], ContentLoss) or isinstance(model[i], StyleLoss):
break
model = model[:(i + 1)]
return model, style_losses, content_losses
After this comes the training loop, which includes line 243 and 188.
Here’s the entire training loop:
training_loader_input = np.array((128,128,3), np.uint8)
for batch in training_loader_content:
for catch in training_loader_style:
content_image = batch
style_image = catch
#LOSS FUNCTION
def get_input_optimizer(training_loader_input):
# this line to show that input is a parameter that requires a gradient
optimizer = optim.LBFGS([training_loader_input])
return optimizer
def run_style_transfer(cnn, cnn_normalization_mean, cnn_normalization_std,
content_image, style_image, training_loader_input, num_steps=300,
style_weight=1000000, content_weight=1):
"""Run the style transfer."""
print('Building the style transfer model..')
model, style_losses, content_losses = get_style_model_and_losses(cnn,
cnn_normalization_mean, cnn_normalization_std, style_image, content_image)
# We want to optimize the input and not the model parameters so we
# update all the requires_grad fields accordingly
training_loader_input.requires_grad_(True)
model.requires_grad_(True)
optimizer = get_input_optimizer(training_loader_input)
print('Optimizing..')
run = [0]
while run[0] <= num_steps:
def closure():
# correct the values of updated input image
with torch.no_grad():
training_loader_input.clamp_(0, 1)
optimizer.zero_grad()
model(training_loader_input)
style_score = 0
content_score = 0
for sl in style_losses:
style_score += sl.loss
for cl in content_losses:
content_score += cl.loss
style_score *= style_weight
content_score *= content_weight
loss = style_score + content_score
loss.backward()
run[0] += 1
if run[0] % 50 == 0:
print("run {}:".format(run))
print('Style Loss : {:4f} Content Loss: {:4f}'.format(
style_score.item(), content_score.item()))
print()
return style_score + content_score
optimizer.step(closure)
# a last correction...
with torch.no_grad():
training_loader_input.clamp_(0, 1)
return training_loader_input
# add content loss:
output = run_style_transfer(cnn, cnn_normalization_mean, cnn_normalization_std,
content_image, style_image, training_loader_input)
I am very confused with what the normalization missing attributes even mean in this case. Can somebody please help me out?