I am trying to train a UNet for road segmentation. When I normalize the images using transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) the loss decreases but if I normalize the images by dividing them by 255.0 then the loss stops decreasing after a certain point. What is the difference between the two?
transforms.Normalize subtracts the provided mean and divides by the stddev to create standardized tensors (Wikipedia - Standard Score), while the latter approach normalizes the values to the range [0, 1].
but why the first one works efficiently, but the loss for the latter stops decreasing after some time ?
It’s not generally true, I think, and might depend on your application.
You can find literature about how standardizing whitens the input data and this creates a “round” loss surface, but I’m not sure if these simple abstractions are applicable for deep neural networks.
Have a look at this post written by @rasbt for some more information.
3 Likes
In practice, I often find that dividing by 255 works similarly well as z-score standardization (the Normalize approach with means and standard deviation) for images. However, many gradient-based optimization algorithms benefit from the symmetry of having the data centered at 0 with positive and negative values
2 Likes
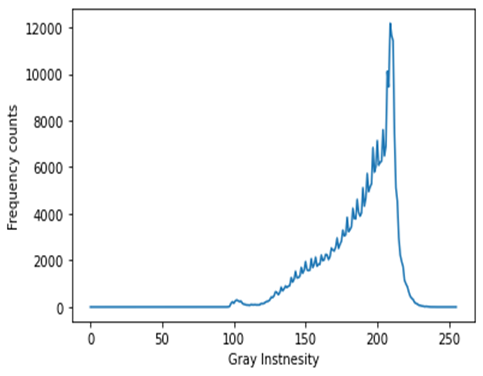
Hello, I am working with BreakHIs dataset ( Breast Histopathology images), and on computing the mean and standard deviation, I get the following values mean=(0.7941, 0.6329, 0.7694), std=(0.1024, 0.1363, 0.0908). However, on using values for normalization, I noticed that the min and max values for my normalized image are around -8 and +3 respectively. Are these values correct? The following is the histogram for one of the original images, it can be seen that the histogram is skewed towards the brighter end.