Training was stopped with the following message: DefaultCPUAllocator: not enough memory: you tried to allocate 58720256 bytes: Buy new RAM!.
However, I assigned 1) my network (binary image classification), 2) input image (N*C*D*H*W = 32*1*7*256*256), and 2) label (32*1) to my GPU (2080Ti). I think the training shouldn’t demand much CPU memory since DataSet (including random image augmentation) and DataLoader are the only processes for CPU.
From Task Manager, I found that the training requires about 24GB from CPU memory.
Why does the training requires much memory from CPU while I used CUDA for training? Thanks in advance!!
24GB seem to be quite a lot.
Are you storing any actications, checkpoints, or preload the dataset?
Could you also post your code so that we could have a look?
I instantiated SummaryWriter (tensorboardX) before training begins and use it to store the graph every epoch via ‘add_graph’ . Would it be the problem?
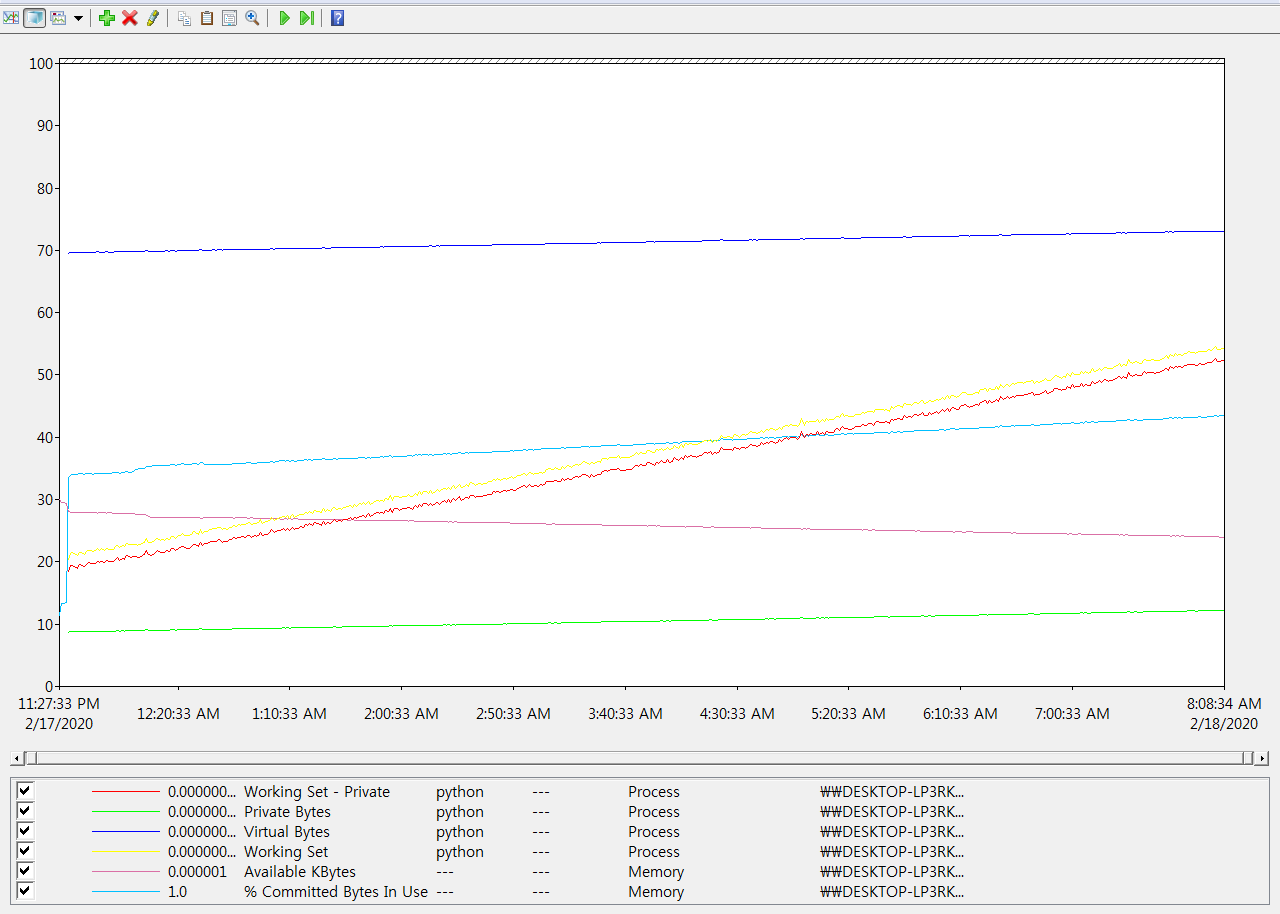
I disabled detect_anomaly and checked the CPU memory usage. I found there had been a memory leaking problem while running this code. However, I found the memory leaking problem maintained even after I disabled detect_anomaly. Below is the result of perfmon (Windows)