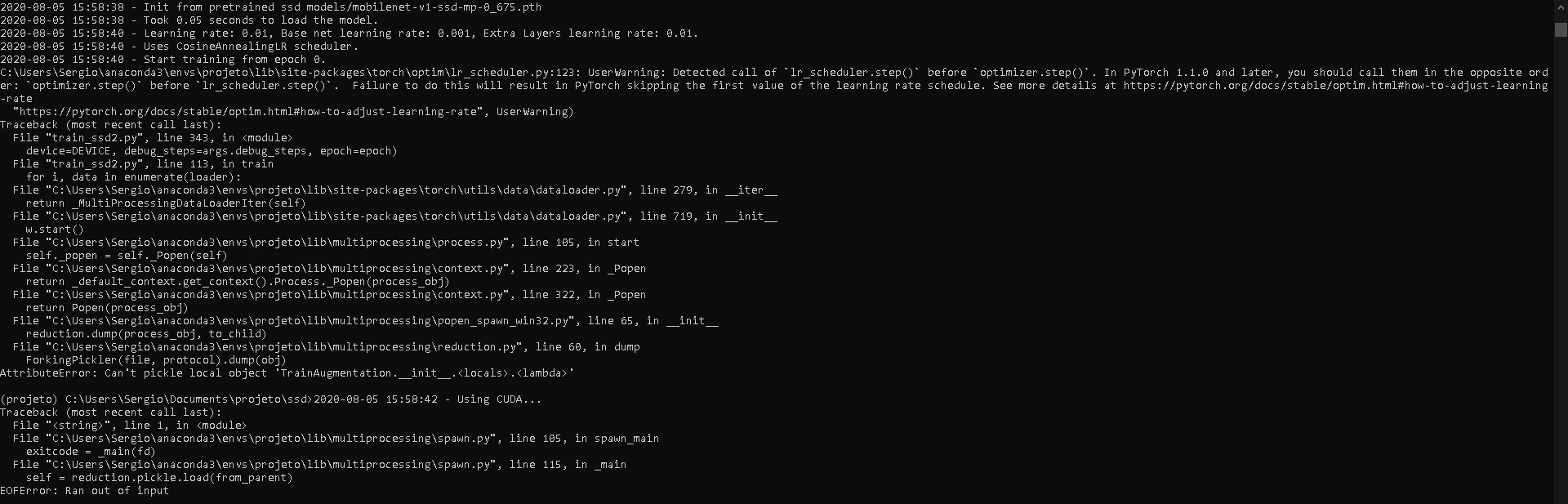
Hi, I am training my dataset using this code below, in linux it runs well and fast but when I try to run on windows I can only run if num-workers = 0 but that makes the process much slower. Does anyone know how I can run this code on windows with num-workers> 0?
import os
import sys
import logging
import argparse
import itertools
import torch
from torch.utils.data import DataLoader, ConcatDataset
from torch.optim.lr_scheduler import CosineAnnealingLR, MultiStepLR
from vision.utils.misc import str2bool, Timer, freeze_net_layers, store_labels
from vision.ssd.ssd import MatchPrior
from vision.ssd.vgg_ssd import create_vgg_ssd
from vision.ssd.mobilenetv1_ssd import create_mobilenetv1_ssd
from vision.ssd.mobilenetv1_ssd_lite import create_mobilenetv1_ssd_lite
from vision.ssd.mobilenet_v2_ssd_lite import create_mobilenetv2_ssd_lite
from vision.ssd.squeezenet_ssd_lite import create_squeezenet_ssd_lite
from vision.datasets.voc_dataset import VOCDataset
from vision.datasets.open_images import OpenImagesDataset
from vision.nn.multibox_loss import MultiboxLoss
from vision.ssd.config import vgg_ssd_config
from vision.ssd.config import mobilenetv1_ssd_config
from vision.ssd.config import squeezenet_ssd_config
from vision.ssd.data_preprocessing import TrainAugmentation, TestTransform
parser = argparse.ArgumentParser(
description='Single Shot MultiBox Detector Training With PyTorch')
# Params for datasets
parser.add_argument("--dataset-type", default="open_images", type=str,
help='Specify dataset type. Currently supports voc and open_images.')
parser.add_argument('--datasets', '--data', nargs='+', default=["data"], help='Dataset directory path')
parser.add_argument('--balance-data', action='store_true',
help="Balance training data by down-sampling more frequent labels.")
# Params for network
parser.add_argument('--net', default="mb1-ssd",
help="The network architecture, it can be mb1-ssd, mb1-lite-ssd, mb2-ssd-lite or vgg16-ssd.")
parser.add_argument('--freeze-base-net', action='store_true',
help="Freeze base net layers.")
parser.add_argument('--freeze-net', action='store_true',
help="Freeze all the layers except the prediction head.")
parser.add_argument('--mb2-width-mult', default=1.0, type=float,
help='Width Multiplifier for MobilenetV2')
# Params for loading pretrained basenet or checkpoints.
parser.add_argument('--base-net', help='Pretrained base model')
parser.add_argument('--pretrained-ssd', default='models/mobilenet-v1-ssd-mp-0_675.pth', type=str, help='Pre-trained base model')
parser.add_argument('--resume', default=None, type=str,
help='Checkpoint state_dict file to resume training from')
# Params for SGD
parser.add_argument('--lr', '--learning-rate', default=0.01, type=float,
help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float,
help='Momentum value for optim')
parser.add_argument('--weight-decay', default=5e-4, type=float,
help='Weight decay for SGD')
parser.add_argument('--gamma', default=0.1, type=float,
help='Gamma update for SGD')
parser.add_argument('--base-net-lr', default=0.001, type=float,
help='initial learning rate for base net, or None to use --lr')
parser.add_argument('--extra-layers-lr', default=None, type=float,
help='initial learning rate for the layers not in base net and prediction heads.')
# Scheduler
parser.add_argument('--scheduler', default="cosine", type=str,
help="Scheduler for SGD. It can one of multi-step and cosine")
# Params for Multi-step Scheduler
parser.add_argument('--milestones', default="80,100", type=str,
help="milestones for MultiStepLR")
# Params for Cosine Annealing
parser.add_argument('--t-max', default=100, type=float,
help='T_max value for Cosine Annealing Scheduler.')
# Train params
parser.add_argument('--batch-size', default=4, type=int,
help='Batch size for training')
parser.add_argument('--num-epochs', default=30, type=int,
help='the number epochs')
parser.add_argument('--num-workers', default=2, type=int,
help='Number of workers used in dataloading')
parser.add_argument('--validation-epochs', default=1, type=int,
help='the number epochs between running validation')
parser.add_argument('--debug-steps', default=10, type=int,
help='Set the debug log output frequency.')
parser.add_argument('--use-cuda', default=True, type=str2bool,
help='Use CUDA to train model')
parser.add_argument('--checkpoint-folder', '--model-dir', default='models/',
help='Directory for saving checkpoint models')
logging.basicConfig(stream=sys.stdout, level=logging.INFO,
format='%(asctime)s - %(message)s', datefmt="%Y-%m-%d %H:%M:%S")
args = parser.parse_args()
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() and args.use_cuda else "cpu")
if args.use_cuda and torch.cuda.is_available():
torch.backends.cudnn.benchmark = True
logging.info("Using CUDA...")
def train(loader, net, criterion, optimizer, device, debug_steps=100, epoch=-1):
net.train(True)
running_loss = 0.0
running_regression_loss = 0.0
running_classification_loss = 0.0
for i, data in enumerate(loader):
images, boxes, labels = data
images = images.to(device)
boxes = boxes.to(device)
labels = labels.to(device)
optimizer.zero_grad()
confidence, locations = net(images)
regression_loss, classification_loss = criterion(confidence, locations, labels, boxes) # TODO CHANGE BOXES
loss = regression_loss + classification_loss
loss.backward()
optimizer.step()
running_loss += loss.item()
running_regression_loss += regression_loss.item()
running_classification_loss += classification_loss.item()
if i and i % debug_steps == 0:
avg_loss = running_loss / debug_steps
avg_reg_loss = running_regression_loss / debug_steps
avg_clf_loss = running_classification_loss / debug_steps
logging.info(
f"Epoch: {epoch}, Step: {i}/{len(loader)}, " +
f"Avg Loss: {avg_loss:.4f}, " +
f"Avg Regression Loss {avg_reg_loss:.4f}, " +
f"Avg Classification Loss: {avg_clf_loss:.4f}"
)
running_loss = 0.0
running_regression_loss = 0.0
running_classification_loss = 0.0
def test(loader, net, criterion, device):
net.eval()
running_loss = 0.0
running_regression_loss = 0.0
running_classification_loss = 0.0
num = 0
for _, data in enumerate(loader):
images, boxes, labels = data
images = images.to(device)
boxes = boxes.to(device)
labels = labels.to(device)
num += 1
with torch.no_grad():
confidence, locations = net(images)
regression_loss, classification_loss = criterion(confidence, locations, labels, boxes)
loss = regression_loss + classification_loss
running_loss += loss.item()
running_regression_loss += regression_loss.item()
running_classification_loss += classification_loss.item()
return running_loss / num, running_regression_loss / num, running_classification_loss / num
if __name__ == '__main__':
timer = Timer()
logging.info(args)
# make sure that the checkpoint output dir exists
if args.checkpoint_folder:
args.checkpoint_folder = os.path.expanduser(args.checkpoint_folder)
if not os.path.exists(args.checkpoint_folder):
os.mkdir(args.checkpoint_folder)
# select the network architecture and config
if args.net == 'vgg16-ssd':
create_net = create_vgg_ssd
config = vgg_ssd_config
elif args.net == 'mb1-ssd':
create_net = create_mobilenetv1_ssd
config = mobilenetv1_ssd_config
elif args.net == 'mb1-ssd-lite':
create_net = create_mobilenetv1_ssd_lite
config = mobilenetv1_ssd_config
elif args.net == 'sq-ssd-lite':
create_net = create_squeezenet_ssd_lite
config = squeezenet_ssd_config
elif args.net == 'mb2-ssd-lite':
create_net = lambda num: create_mobilenetv2_ssd_lite(num, width_mult=args.mb2_width_mult)
config = mobilenetv1_ssd_config
else:
logging.fatal("The net type is wrong.")
parser.print_help(sys.stderr)
sys.exit(1)
# create data transforms for train/test/val
train_transform = TrainAugmentation(config.image_size, config.image_mean, config.image_std)
target_transform = MatchPrior(config.priors, config.center_variance,
config.size_variance, 0.5)
test_transform = TestTransform(config.image_size, config.image_mean, config.image_std)
# load datasets (could be multiple)
logging.info("Prepare training datasets.")
datasets = []
for dataset_path in args.datasets:
if args.dataset_type == 'voc':
dataset = VOCDataset(dataset_path, transform=train_transform,
target_transform=target_transform)
label_file = os.path.join(args.checkpoint_folder, "labels.txt")
store_labels(label_file, dataset.class_names)
num_classes = len(dataset.class_names)
elif args.dataset_type == 'open_images':
dataset = OpenImagesDataset(dataset_path,
transform=train_transform, target_transform=target_transform,
dataset_type="train", balance_data=args.balance_data)
label_file = os.path.join(args.checkpoint_folder, "labels.txt")
store_labels(label_file, dataset.class_names)
logging.info(dataset)
num_classes = len(dataset.class_names)
else:
raise ValueError(f"Dataset type {args.dataset_type} is not supported.")
datasets.append(dataset)
# create training dataset
logging.info(f"Stored labels into file {label_file}.")
train_dataset = ConcatDataset(datasets)
logging.info("Train dataset size: {}".format(len(train_dataset)))
train_loader = DataLoader(train_dataset, args.batch_size,
num_workers=args.num_workers,
shuffle=True)
# create validation dataset
logging.info("Prepare Validation datasets.")
if args.dataset_type == "voc":
val_dataset = VOCDataset(dataset_path, transform=test_transform,
target_transform=target_transform, is_test=True)
elif args.dataset_type == 'open_images':
val_dataset = OpenImagesDataset(dataset_path,
transform=test_transform, target_transform=target_transform,
dataset_type="test")
logging.info(val_dataset)
logging.info("Validation dataset size: {}".format(len(val_dataset)))
val_loader = DataLoader(val_dataset, args.batch_size,
num_workers=args.num_workers,
shuffle=False)
# create the network
logging.info("Build network.")
net = create_net(num_classes)
min_loss = -10000.0
last_epoch = -1
# freeze certain layers (if requested)
base_net_lr = args.base_net_lr if args.base_net_lr is not None else args.lr
extra_layers_lr = args.extra_layers_lr if args.extra_layers_lr is not None else args.lr
if args.freeze_base_net:
logging.info("Freeze base net.")
freeze_net_layers(net.base_net)
params = itertools.chain(net.source_layer_add_ons.parameters(), net.extras.parameters(),
net.regression_headers.parameters(), net.classification_headers.parameters())
params = [
{'params': itertools.chain(
net.source_layer_add_ons.parameters(),
net.extras.parameters()
), 'lr': extra_layers_lr},
{'params': itertools.chain(
net.regression_headers.parameters(),
net.classification_headers.parameters()
)}
]
elif args.freeze_net:
freeze_net_layers(net.base_net)
freeze_net_layers(net.source_layer_add_ons)
freeze_net_layers(net.extras)
params = itertools.chain(net.regression_headers.parameters(), net.classification_headers.parameters())
logging.info("Freeze all the layers except prediction heads.")
else:
params = [
{'params': net.base_net.parameters(), 'lr': base_net_lr},
{'params': itertools.chain(
net.source_layer_add_ons.parameters(),
net.extras.parameters()
), 'lr': extra_layers_lr},
{'params': itertools.chain(
net.regression_headers.parameters(),
net.classification_headers.parameters()
)}
]
# load a previous model checkpoint (if requested)
timer.start("Load Model")
if args.resume:
logging.info(f"Resume from the model {args.resume}")
net.load(args.resume)
elif args.base_net:
logging.info(f"Init from base net {args.base_net}")
net.init_from_base_net(args.base_net)
elif args.pretrained_ssd:
logging.info(f"Init from pretrained ssd {args.pretrained_ssd}")
net.init_from_pretrained_ssd(args.pretrained_ssd)
logging.info(f'Took {timer.end("Load Model"):.2f} seconds to load the model.')
# move the model to GPU
net.to(DEVICE)
# define loss function and optimizer
criterion = MultiboxLoss(config.priors, iou_threshold=0.5, neg_pos_ratio=3,
center_variance=0.1, size_variance=0.2, device=DEVICE)
optimizer = torch.optim.SGD(params, lr=args.lr, momentum=args.momentum,
weight_decay=args.weight_decay)
logging.info(f"Learning rate: {args.lr}, Base net learning rate: {base_net_lr}, "
+ f"Extra Layers learning rate: {extra_layers_lr}.")
# set learning rate policy
if args.scheduler == 'multi-step':
logging.info("Uses MultiStepLR scheduler.")
milestones = [int(v.strip()) for v in args.milestones.split(",")]
scheduler = MultiStepLR(optimizer, milestones=milestones,
gamma=0.1, last_epoch=last_epoch)
elif args.scheduler == 'cosine':
logging.info("Uses CosineAnnealingLR scheduler.")
scheduler = CosineAnnealingLR(optimizer, args.t_max, last_epoch=last_epoch)
else:
logging.fatal(f"Unsupported Scheduler: {args.scheduler}.")
parser.print_help(sys.stderr)
sys.exit(1)
# train for the desired number of epochs
logging.info(f"Start training from epoch {last_epoch + 1}.")
for epoch in range(last_epoch + 1, args.num_epochs):
scheduler.step()
train(train_loader, net, criterion, optimizer,
device=DEVICE, debug_steps=args.debug_steps, epoch=epoch)
if epoch % args.validation_epochs == 0 or epoch == args.num_epochs - 1:
val_loss, val_regression_loss, val_classification_loss = test(val_loader, net, criterion, DEVICE)
logging.info(
f"Epoch: {epoch}, " +
f"Validation Loss: {val_loss:.4f}, " +
f"Validation Regression Loss {val_regression_loss:.4f}, " +
f"Validation Classification Loss: {val_classification_loss:.4f}"
)
model_path = os.path.join(args.checkpoint_folder, f"{args.net}-Epoch-{epoch}-Loss-{val_loss}.pth")
torch.save(net.state_dict(),model_path)
logging.info(f"Saved model {model_path}")
logging.info("Task done, exiting program.")