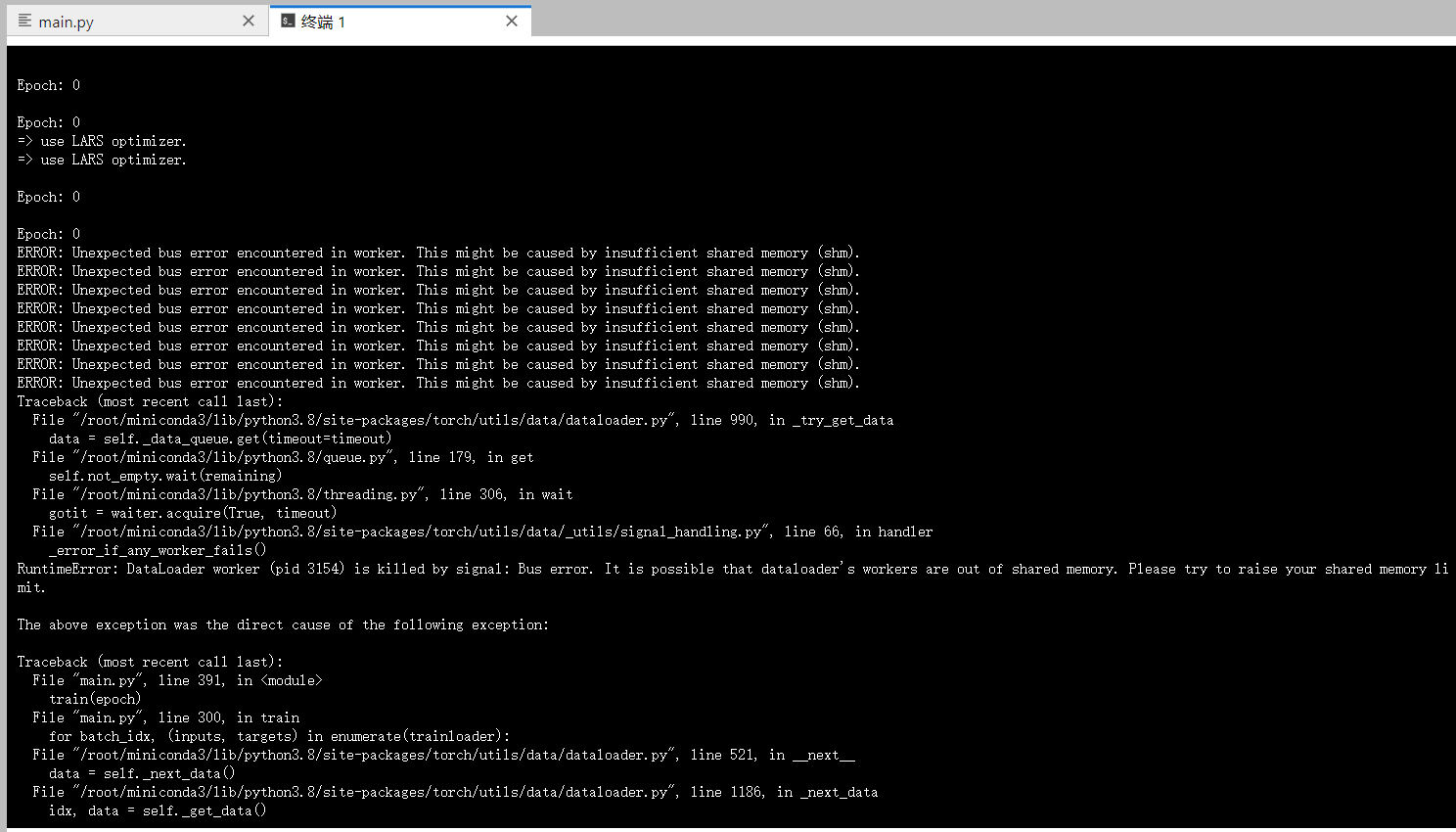
I try to training imagenet on four 3090 graph cards with 4096 batchsize. However, when I set num_works bigger than 8, this erorr shut down my training program.

Did you try to increase your shared memory limit or checked which limit is currently set?
I am working on a leased server. The shared memory of virtual environment is 20G. I can’t change this setting. Is there any method to avoid this issue?
Assuming you are indeed using all 20GB of it, I think the only workaround would be to reduce the shared memory usage by reducing the number of workers.