I have created a custom layer in which i have initialized a glorot uniform weight given input_shape = (1,3,299,299).
class CustomLayer(torch.nn.Module):
def __init__(self, input_shape):
super(CustomLayer,self).__init__()
zeros = torch.zeros(input_shape)
self.weights = torch.nn.Parameter(zeros)
torch.nn.init.xavier_uniform_(self.weights)
def forward(self, x):
out= torch.tanh(self.weights)
return out+x
class MimicAndFool(torch.nn.Module):
def __init__(self,input_shape):
super(MimicAndFool,self).__init__()
self.custom = CustomLayer(input_shape)
def forward(self,x):
out = self.custom(x)
#statement 2
#statement 3...
#statement n
return out
After I print the summary
input_shape = (1,3,299,299)
maf = MimicAndFool(input_shape)
summary(maf,(3,299,299))
It says that the number of parameters for this custom layer is zero!
Please tell me what I’m missing out on . The number of parameters should have been = 3 * 299 * 299 = 268203
ptrblck
September 28, 2020, 9:14am
2
Your custom layer contains the weigth parameter printed by this code snippet:
class CustomLayer(torch.nn.Module):
def __init__(self, input_shape):
super(CustomLayer,self).__init__()
zeros = torch.zeros(input_shape)
self.weights = torch.nn.Parameter(zeros)
torch.nn.init.xavier_uniform_(self.weights)
def forward(self, x):
out= torch.tanh(self.weights)
return out+x
class MimicAndFool(torch.nn.Module):
def __init__(self,input_shape):
super(MimicAndFool,self).__init__()
self.custom = CustomLayer(input_shape)
def forward(self,x):
out = self.custom(x)
#statement 2
#statement 3...
#statement n
return out
layer = CustomLayer((1, 1))
print(dict(layer.named_parameters()))
> {'weights': Parameter containing:
tensor([[-0.7979]], requires_grad=True)}
module = MimicAndFool((1, 1))
print(dict(module.named_parameters()))
> {'custom.weights': Parameter containing:
tensor([[0.8589]], requires_grad=True)}
so I assume torchsummary might not return the right values for this custom module.
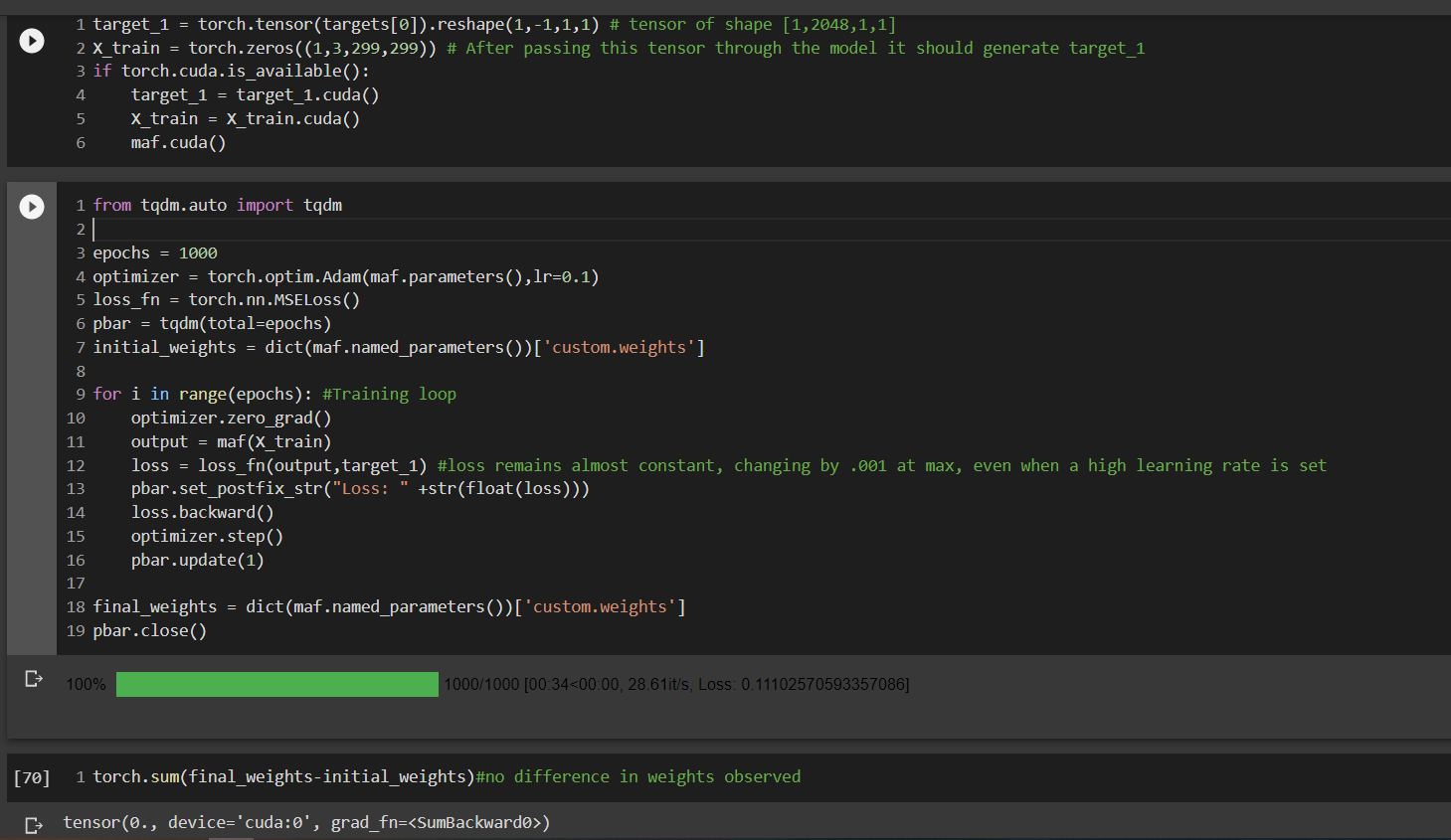
So I tried training the model, but the loss remains almost the same. The difference between the initial weights and final weights turn out to be zero, meaning that no training has actually happened for those weights. I’ve frozen all of the other layers except the custom layer.
ptrblck
September 28, 2020, 8:08pm
5
Could you check, if you get valid gradients in the custom module by calling
print(model.custom.weights.grad)
after the backward() call?
I do get grads for every iteration but they are very small it seems.
Oh i found out the reason why the final - initial weights were giving me a zero tensor
Hello, I have the same question with you.

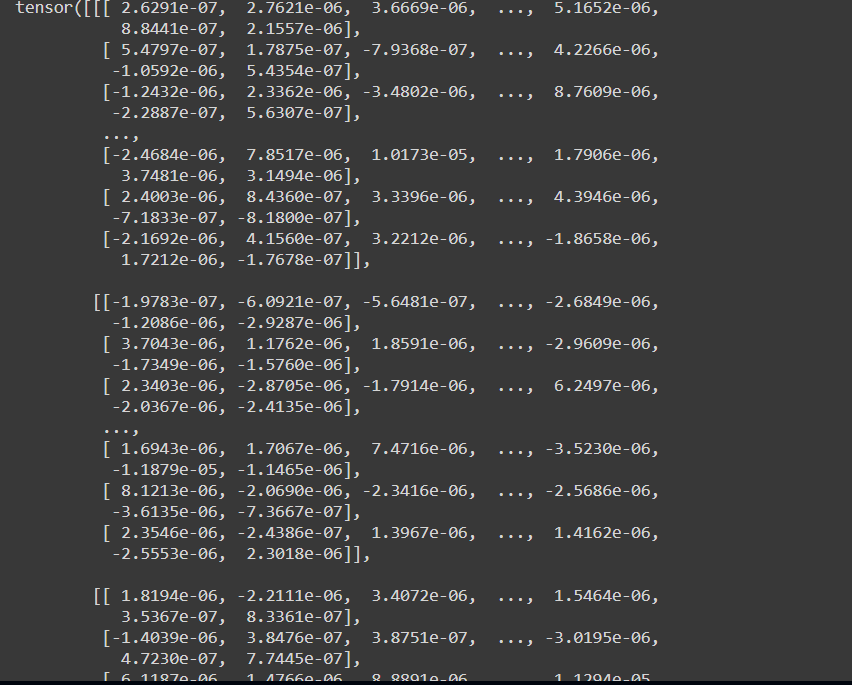
 . They were both pointing to the same object, when I printed them I got to know their difference.
. They were both pointing to the same object, when I printed them I got to know their difference.