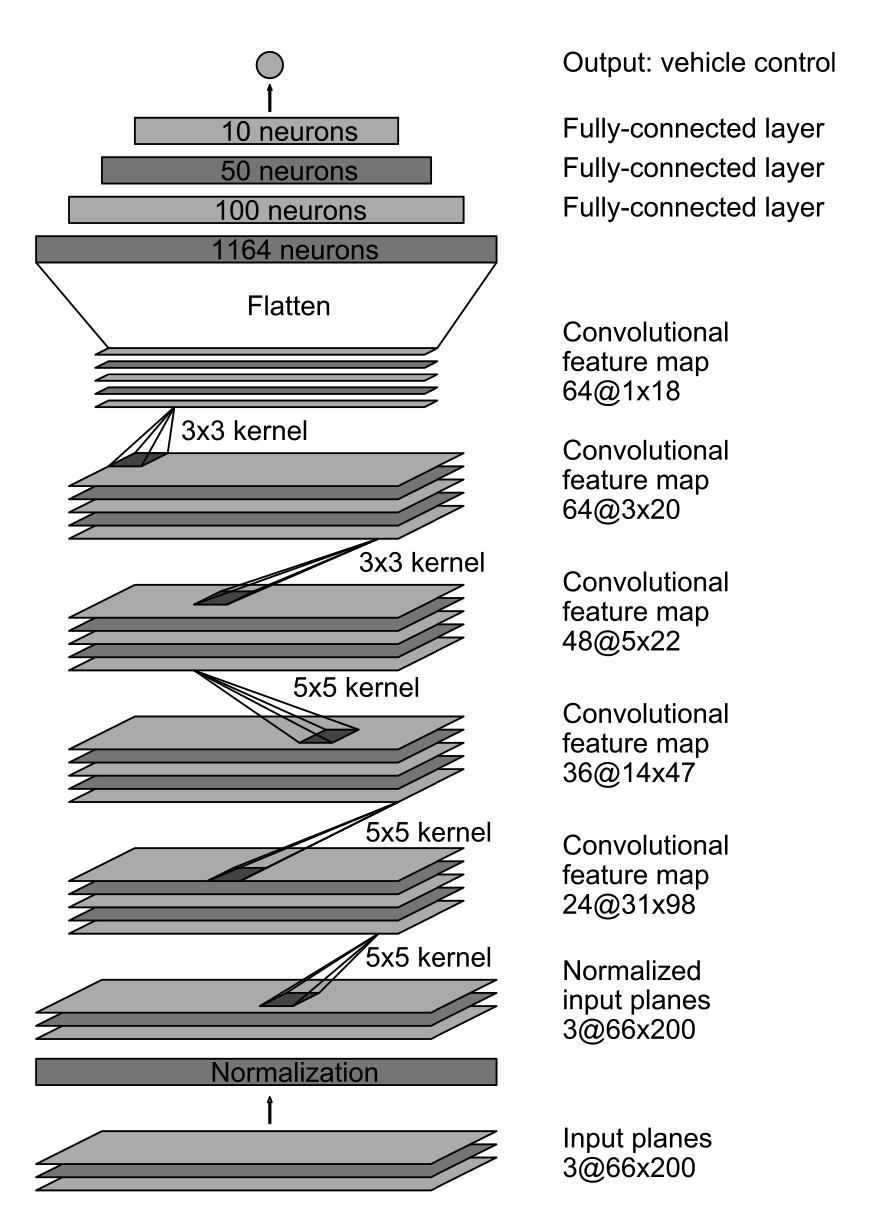
I want a CNN designed by NVIDIA to work on a regression task of “Driving image to steering angle prediction”. Although the model (image 1) was designed for a slightly different task (with driving images and other signals), I was planning to try this first and modify along for my purposes.
I have studied code from various people who implemented this model to try a bunch of different strategies:
Normalize pixels in range (0,1), in the range (-1,1) and z-score normalization (separately)
One Dropout 0.2 between CONV 2 and 3 layers (also tried 0.4)
One Dropout of 0.2 between CONV and Linear layers (also tried 0.4, 0.5)
Batch normalization after each convolutional layer
Reduction of model complexity (removal of CONV and Linear layers)
Different values of LR, Batch
Different variations of filter sizes, stride and linear layers
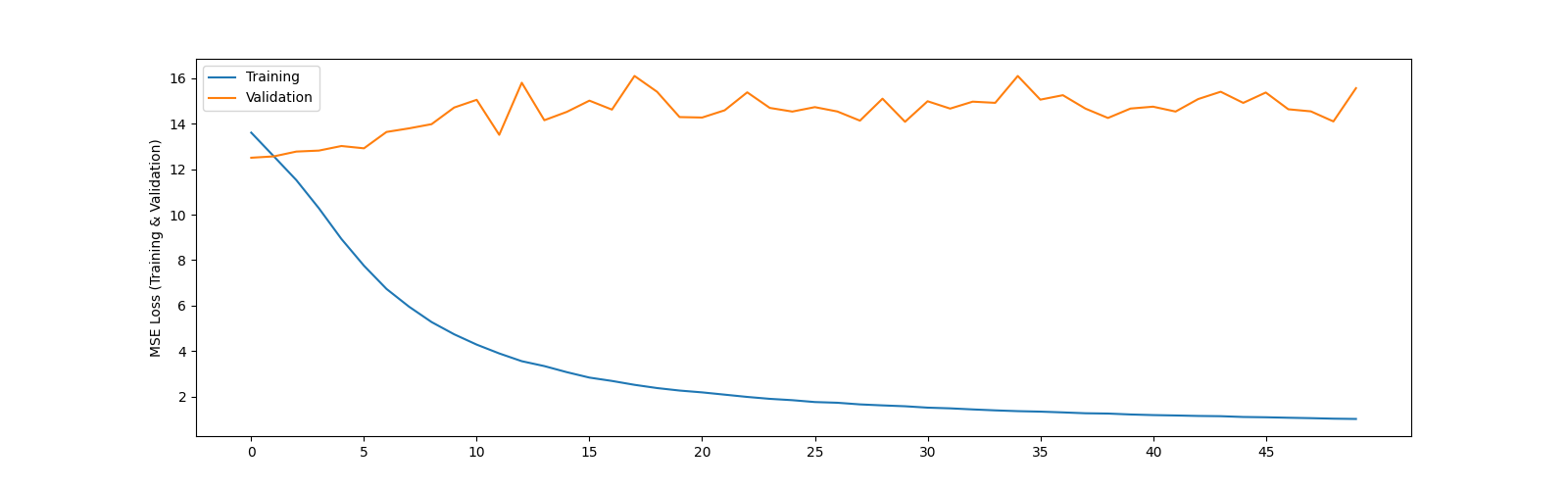
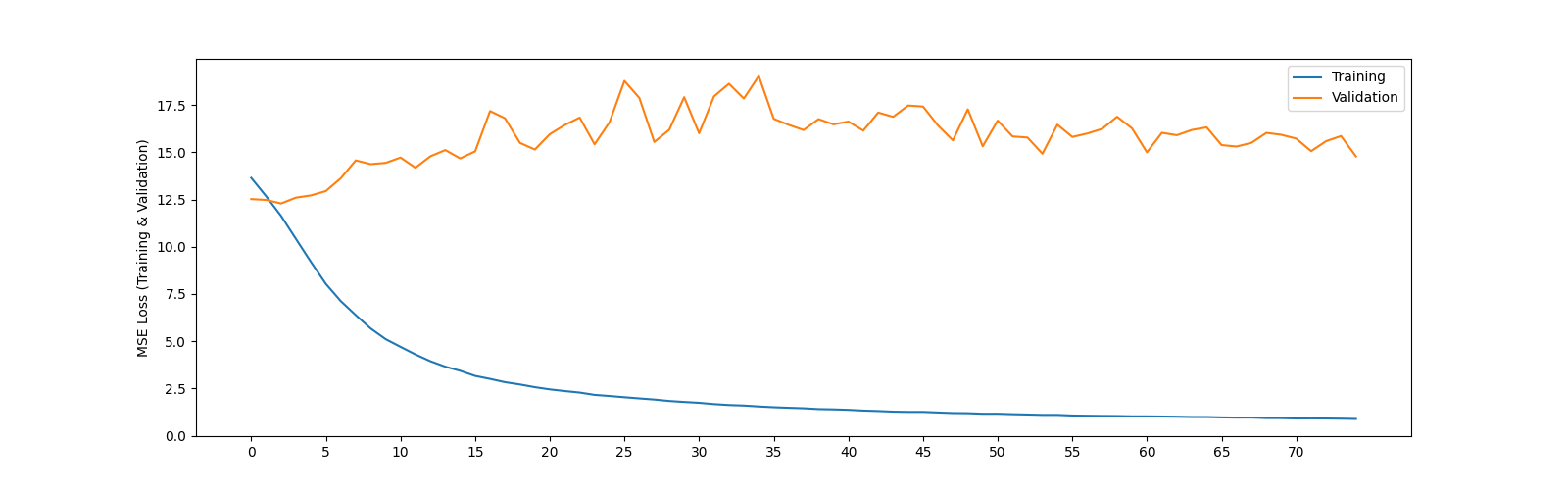
However, despite trying about many many variations of the model for the entire day today, I am still not able to get validation loss to decrease (see figure 2)
Although the model architecture looks relatively nonstandard (pure convolution, extensive use of 5x5 convolutions, no residual layers), the overfitting might be attributable to the dataset. What is the extent of the training and validation set here, and is the data distribution comparable? For example, are the road conditions similar, orientation of camera comparable, etc.?
Thank you for your reply. Sorry, I forgot to mention about the dataset.
Its from Honda and Waymo (on real road images not in simulation), each image has size (220, 66, 3)
There are about 2,50,000 images in training set and about 43,000 in validation.
And yes the data distribution is comparable. Similar angles and road conditions. Although inherently driving data is a little bit non identically distributed.
Yes, Data Augmentation with:
Random selection of various lighting, brightness, contrast, saturation and hue conditions
Spatial shift, rotation, flip and perspective
are in my considerations for the future. However, I was under the impression that I should be able to get at least some generalization with the current version of the model and pipeline as well. And that Augmentation would help improve that performance.
Please feel free to add your thoughts and comments on this.
I appreciate you taking the time to answer.
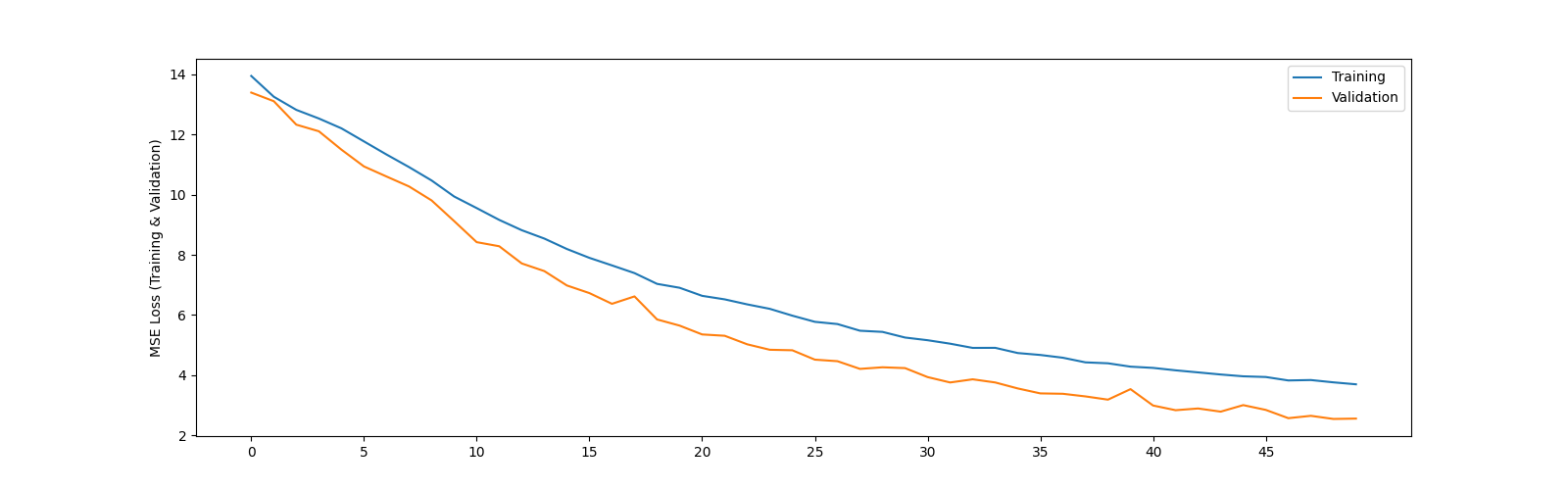
To check if it is indeed a distribution or issue of problem difficulty, I would try to first debug the system by replacing the validation set with the training set and seeing if the results match the training set.
If this works I would try splitting the training set in half and seeing if training on the first half of the training set generalizes well to the second.
Note the validation error is very high.
Now would it be correct for me to say, “The problem we face is not due to distribution shift between Training and Validation sets but rather the problem difficulty of learning with generalization”. Because, even when the data was from the same distribution it did not generalize.
Next I am going to try data augmentation (which I believe has been proven to improve generalization as well as to better performance in training). Are there any specific strategies you know that I should follow?
However, there may still be parts of the model architecture that make it more prone to overfitting. For example, a flatten operation rather than average pooling (or some other kind of layer that removes spatial dependencies) before the fully connected layers may cause the model to be more dependent on non-generalizable features. You might want to see if the results improve with a modified ResNet or other popular vision architecture.
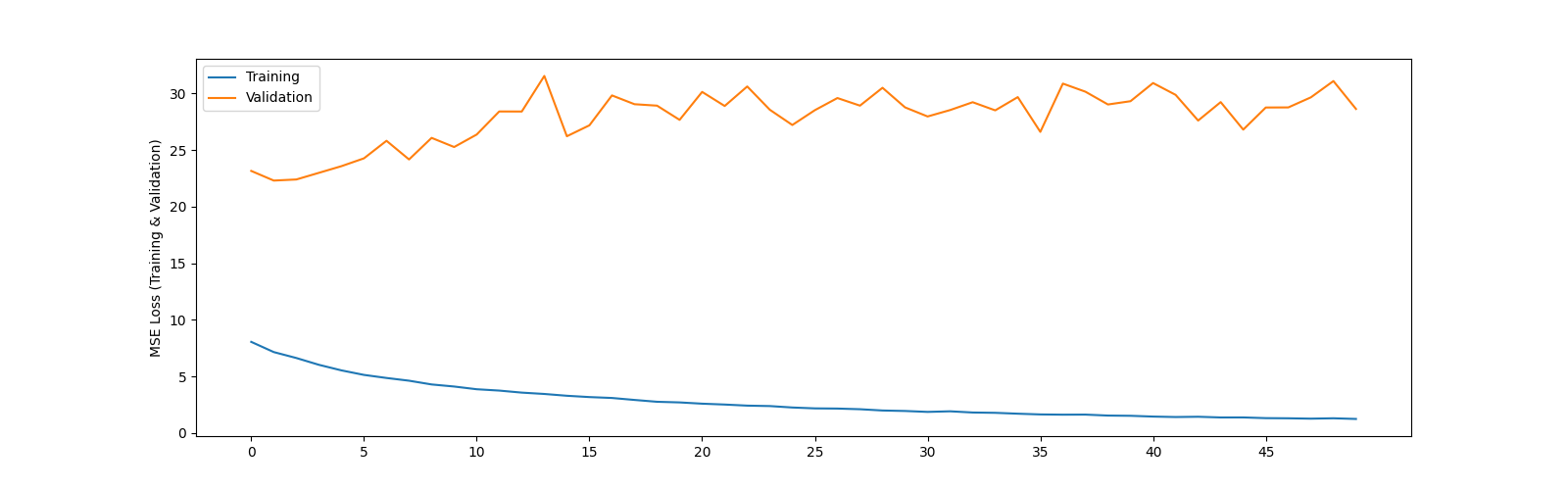
I did a data augmentation where for every image there is a transformed image with one of the 13 transforms from this list: [Random Color Jitter (Hue, Saturation, Contrast, Brightness), Horizontal Flip, Vertical Flip, Histogram Equalization, Auto Contrast, Adjust Shaprness, Solarize, Posterize , Invert, Affine Transformation, Random rotation , Random Perspective shift, Gaussian Blur]
Next, I coded up the ResNet 50 architecture but seems like it will take a while to train (23 million parameters and train data size = 4,30,000). Will update after overnight of running on ResNet.