Hi,
I’m following the tutorial TorchVision Object Detection Finetuning Tutorial — PyTorch Tutorials 1.8.1+cu102 documentation
applying the code to cityscapes dataset, with format of the dataset appropriately modified to match the format requested.
Once I start the training loop as in the tutorial, the training starts but after the first epoch it stops, giving me the following error:
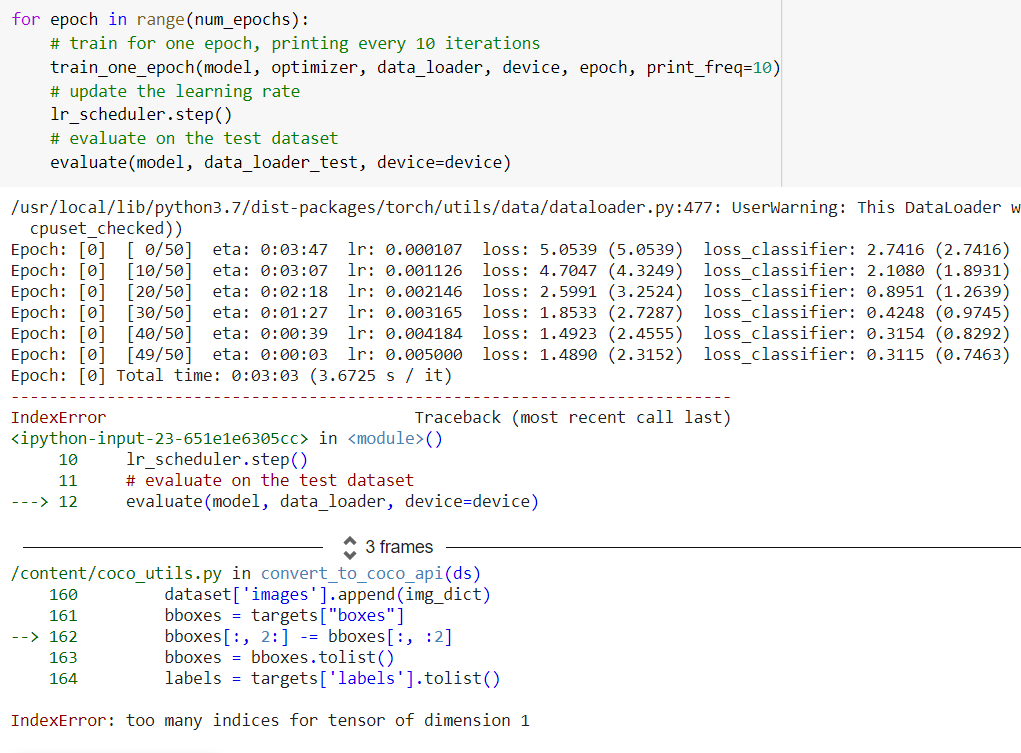
However I don’t understand why I get this error, because my tensor of boxes is (like in the tutorial) a tensor with 4 elements for each instance, representing each box inside a given image.
Can you help me please? Thanks in advance
I post also the code of dataset loading (you can ignore the comments, they were just to resize input data in a second moment :
class my_CocoDetection(VisionDataset):
"""`MS Coco Detection <https://cocodataset.org/#detection-2016>`_ Dataset.
Args:
root (string): Root directory where images are downloaded to.
annFile (string): Path to json annotation file.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.ToTensor``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
transforms (callable, optional): A function/transform that takes input sample and its target as entry
and returns a transformed version.
"""
def __init__(self, root, annFile, transforms = None):
self.root = root
self.annFile = annFile
self.transforms = transforms
# root: str,
# annFile: str,
# do_transforms=None
# transform: Optional[Callable] = None,
# target_transform: Optional[Callable] = None,
# transforms: Optional[Callable] = None,
# ) -> None:
# super(my_CocoDetection, self).__init__(root, annFile) #, transform, target_transform)
from pycocotools.coco import COCO
self.coco = COCO(annFile)
self.ids = list(sorted(self.coco.imgs.keys()))
def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""
Args:
index (int): Index
Returns:
tuple: Tuple (image, target). target is the object returned by ``coco.loadAnns``.
"""
coco = self.coco
img_id = self.ids[index]
ann_ids = coco.getAnnIds(imgIds=img_id)
target = coco.loadAnns(ann_ids)
path = coco.loadImgs(img_id)[0]['file_name']
img = Image.open(os.path.join(self.root, path)).convert('RGB')
# # resize the image to lower resolution
# img = img.resize((1024, 512))
width = img.size[0]
heigth = img.size[1]
boxes = []
masks = []
class_ids = []
image_id = index
iscrowd_list = []
areas = []
for elem in target:
if(len(elem['bbox'])<4):
print("!!!WARNING!! - found non 4 boxes for element")
print("skipping to next image...")
#continue
# sort the box coordinates in the right order
xmin = elem['bbox'][0] #np.int(elem['bbox'][0] /2)
xmax = xmin + elem['bbox'][2 ]#xmin + np.int(elem['bbox'][2] /2)
ymin = elem['bbox'][1] #np.int(elem['bbox'][1] /2)
ymax = ymin + elem['bbox'][3] #ymin + np.int(elem['bbox'][3])
# assert xmin < xmax, "xmin should be less than xmax"
# assert ymin < ymax, "ymin should be less than ymax"
boxes.append([xmin, ymin, xmax, ymax])
mask = self.annToMask(elem['segmentation'], heigth, width)
# # resize mask to match image size
# mask = Image.fromarray(mask) # convert np image in PIL
# mask = mask.resize((1024, 512)) # resize
# mask = np.array(mask) # convert back
masks.append(mask)
class_ids.append(elem['category_id'])
#image_ids.append(elem['image_id'])
iscrowd_list.append(elem['iscrowd'])
# compute area and append to list
areas.append(elem['area']) # np.int(elem['area']/4))
# convert everything into a torch.Tensor
boxes = torch.as_tensor(boxes, dtype=torch.float32)
masks = torch.as_tensor(masks, dtype=torch.uint8)
class_ids = torch.as_tensor(class_ids, dtype=torch.int64)
image_id = torch.tensor(image_id)
iscrowd_list = torch.as_tensor(iscrowd_list, dtype=torch.int64)
areas = torch.as_tensor(areas, dtype=torch.float32)
# changed the name inside brackets because this format is required
# in the train_one_epoch method
gt_instances = {}
gt_instances['boxes'] = boxes
gt_instances['masks'] = masks
gt_instances['labels'] = class_ids
gt_instances['image_id'] = image_id
gt_instances['iscrowd'] = iscrowd_list
gt_instances['area'] = areas
if self.transforms is not None:
img, gt_instances = self.transforms(img, gt_instances)
return img, gt_instances
def __len__(self) -> int:
return len(self.ids)
def annToRLE(self, ann, height, width):
"""
Convert annotation which can be polygons, uncompressed RLE to RLE.
:return: binary mask (numpy 2D array)
"""
segm = ann #ann['segmentation']
if isinstance(segm, list):
# polygon -- a single object might consist of multiple parts
# we merge all parts into one mask rle code
rles = maskUtils.frPyObjects(segm, height, width)
rle = maskUtils.merge(rles)
elif isinstance(segm['counts'], list):
# uncompressed RLE
rle = maskUtils.frPyObjects(segm, height, width)
else:
# rle
rle = ann['segmentation']
return rle
def annToMask(self, ann, height, width):
"""
Convert annotation which can be polygons, uncompressed RLE, or RLE to binary mask.
:return: binary mask (numpy 2D array)
"""
rle = self.annToRLE(ann, height, width)
m = maskUtils.decode(rle)
return m