I am currently working on a small toy-project that involves object detection as one of the steps.
Currently, I amusing a pre-trained Faster-RCNN from Detectron2 with ResNet-101 backbone.
I wanted to make an MVP and show it to my colleagues, so I thought of deploying my model on a CPU machine. Detectron2 can be easily converted to Caffe2 (DOCS) for the deployment.
I measured the inference times for GPU and the CPU mode. The inference time of the original Detectron2 model using PyTorch and GPU is around 90ms on my RTX2080 Ti.
The converted model on CPU (i9 9940X) and using Caffe2 API took 2.4s. I read that the Caffe2 is optimized for CPU inference, so I am quite surprised by the inference time on CPU. I asked about this situation on the Detectron2 GitHub and I got an answer like: „Expected inference time of R-50-FPN Faster R-CNN on a 8 core CPU is around 1.9s. Usually, ResNets are not used on CPUs.”
There is my question, how such deep learning solutions for Computer Vision should be deployed in the real-world? I read somewhere that Facebook does use Caffe2 for their production models as CPUs are super cheap compared to GPUs (of course they are), but the difference in the running time is really huge. Using CPU for object detection seems useless for any real-time application.
Should I use some other architecture, which does not include ResNet or Faster-RCNN (like YOLO v4/v3, SSD, etc.)? Or maybe the original GPU-trained model should be converted to ONNX and then used in other more CPU-optimized frameworks such as OpenVINO? Or there are some other tweaks such as quantization, pruning, etc. that are necessary to boost the CPU-inference efficiency of production models?
I know that this is just a toy-project (for now at least), I can use GPU for inference (quite costly in real applications?) or just use other architecture (but sacrifice performance). I am just wondering what is the go-to solution for real-world systems.
Thanks in advance for sharing your knowledge and experience. I will be grateful for any hints!
I am not a big expert in this area but just for letting know what I have discovered.
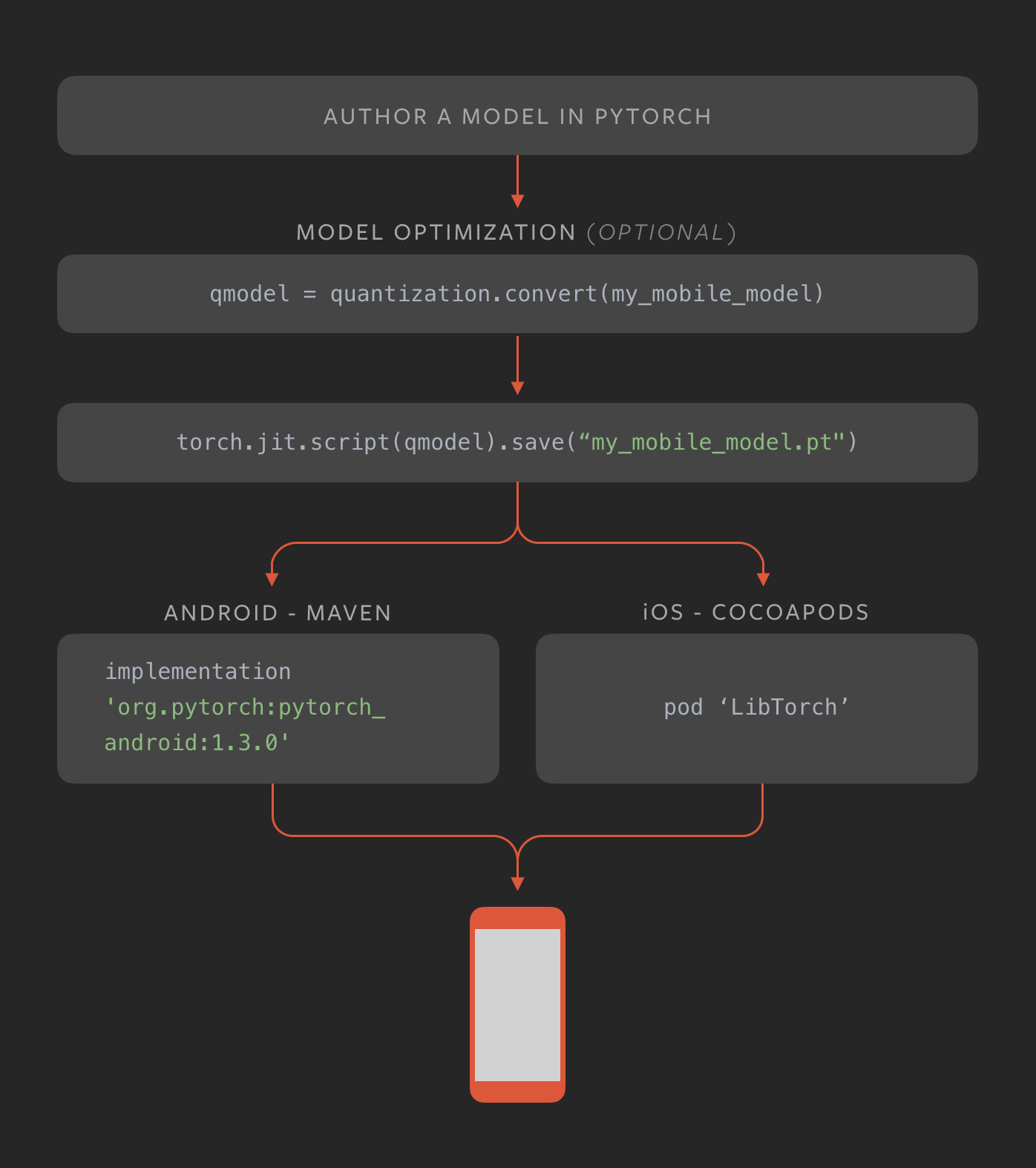
Converting PyTorch models to TorchScripts models is a good idea. You get a file that contains the arch class and weights. In the first run of the model gets optimized and after that is pretty fast. I am getting around 1.98 s ± 42.1 ms in my Ryzen 1700 with Mask-RCNN Resnet 50 (the implementation of torchvision).
I have also discovered quantization . It optimizes models and make them able to run on a mobile or arm devices like Raspberry. However, after quantization the model losses some precision. Here you have an image explaining the process:
Thanks for sharing this.
I am about to check the quantization, but I did not think about using TorchScript. Thanks!
Even though your running time of Mask-RCNN is better than my detector I feel still dissatisfied with inference time around 2s. I would be glad if the detector could run in around 1s; that would be acceptable for my settings, but I am not sure if this is feasible for Faster-RCNN & CPU.
I tried something similar as you did and also began with a RCNN and also had to realize that the RCNN is indeed slow. In my experience SSD and in particular SSDLite is accurate and fast.
Yes, I think the RCNN is a dead-end for CPU inference. However, Facebook does use object detection algorithms on CPUs (that’s what I found on their GitHub and on some articles), but I am not sure if the use RCNN actually.
@WaterKnight Do you know how I generate the APK of the Torch Scripts version to run within the Android version? What type of database do I use to store model data? I’m trying to generate a version to be used on Android. Any tips? I’m using Mask-RCNN based on Detectron2.
I just found this thread recently. I think I am dealing with similar performance issue of deploying object detection model on CPU.
I am running Faster RCNN object detection model built on pytorch. The hardware is an AWS EC2 instance (T2.large with Intel Xeon, clock speed of 3.3 GHz). I am getting inference time of ~3 sec per frame. This seems to be similar to the performance the original poster (bonzogondo) mentioned above.
While I understand GPU is necessary for training a model, but I thought CPU is adequate for running a model in inference mode, (as I have seen real time object detection system running on raspberry pi or android phone) . Is this performance issue specific to Faster RCNN?
Sorry abt the newbie question. Thank you for any advice and insight.