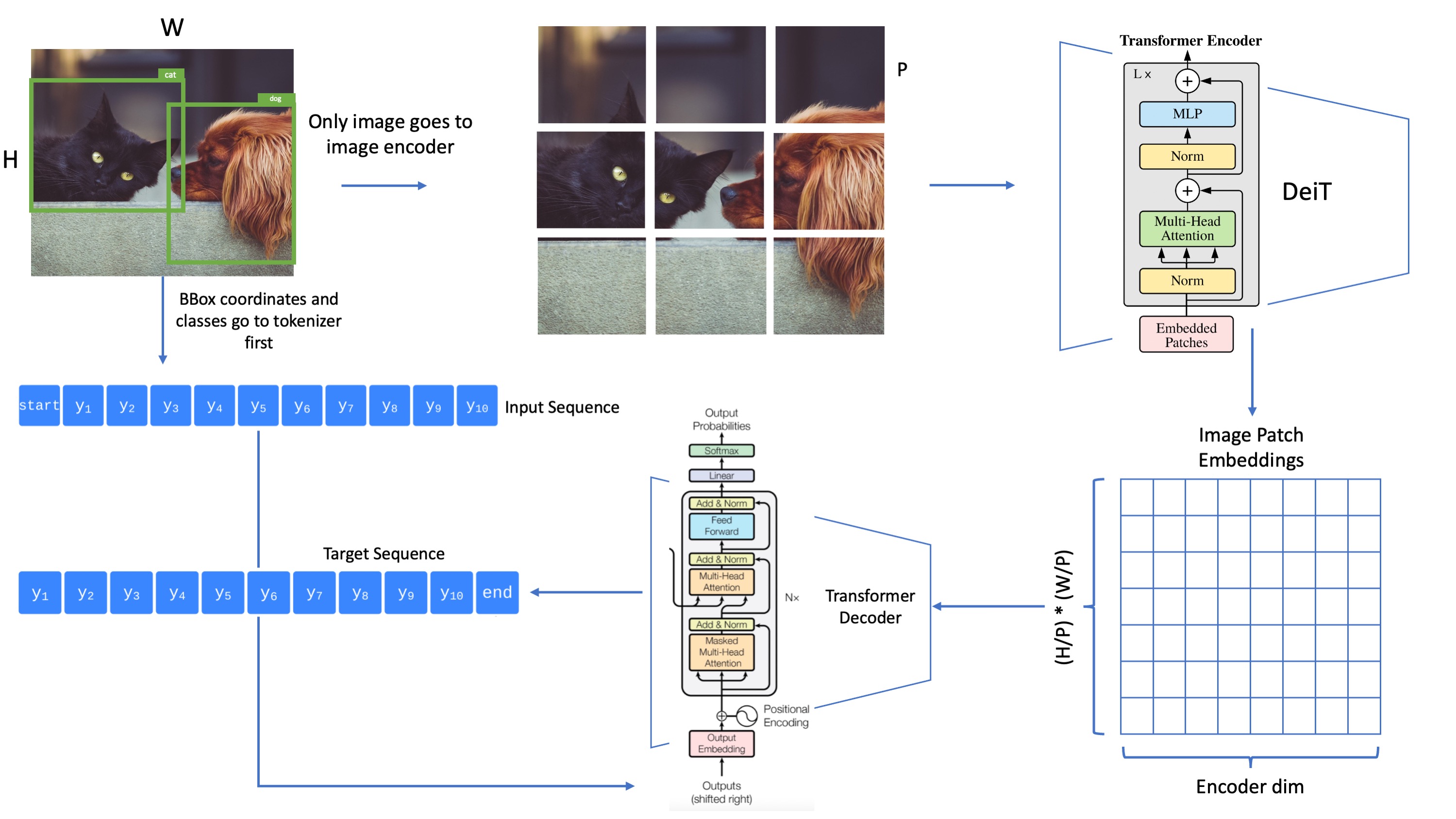
hi! i read the code, i think that noisy inputs are missing. also i suspect that evaluation should be done in autoregressive fashion otherwise you are always using the ground truth of previous timesteps instead of your own prediction
Yes, for the sake of simplicity of my implementation and tutorial, I skipped the augmentation technique they used and that’s one reason why I don’t reach the good performance of the paper.
Regarding the evaluation, I am using “teacher forcing” in my implementation and the mask in decoder self-attention layers ensures the models does not peak on future tokens. You can refer to the issues of the repo where I explain in more depth.
I understand the ‘teacher forcing’ technique. But imagine in a true evaluation mode where you do not have the ground truth, what do you feed the network with? For a true evaluation we need the autoregressive setup, otherwise you are using the ground truth as input sequence of previous timesteps instead of your prediction (being with argmax or nucleus sampling or whatever technique)