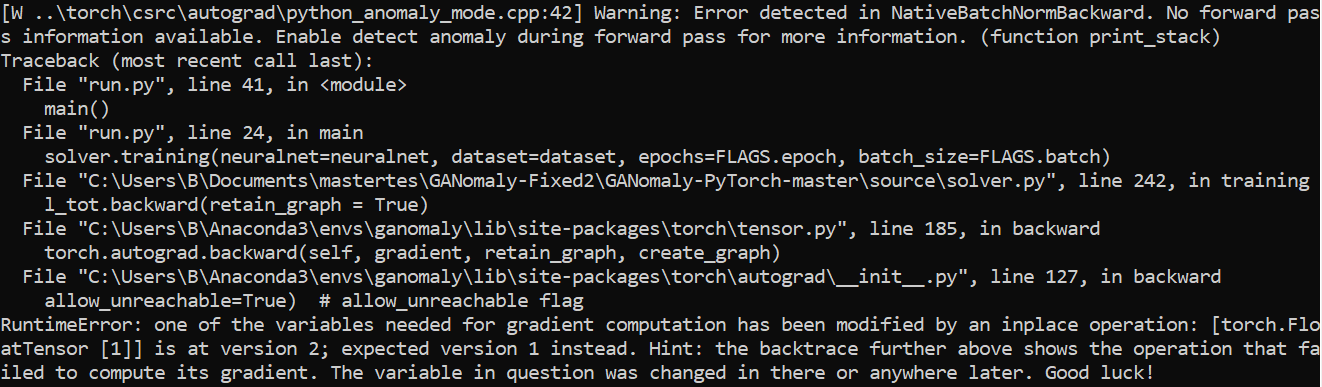
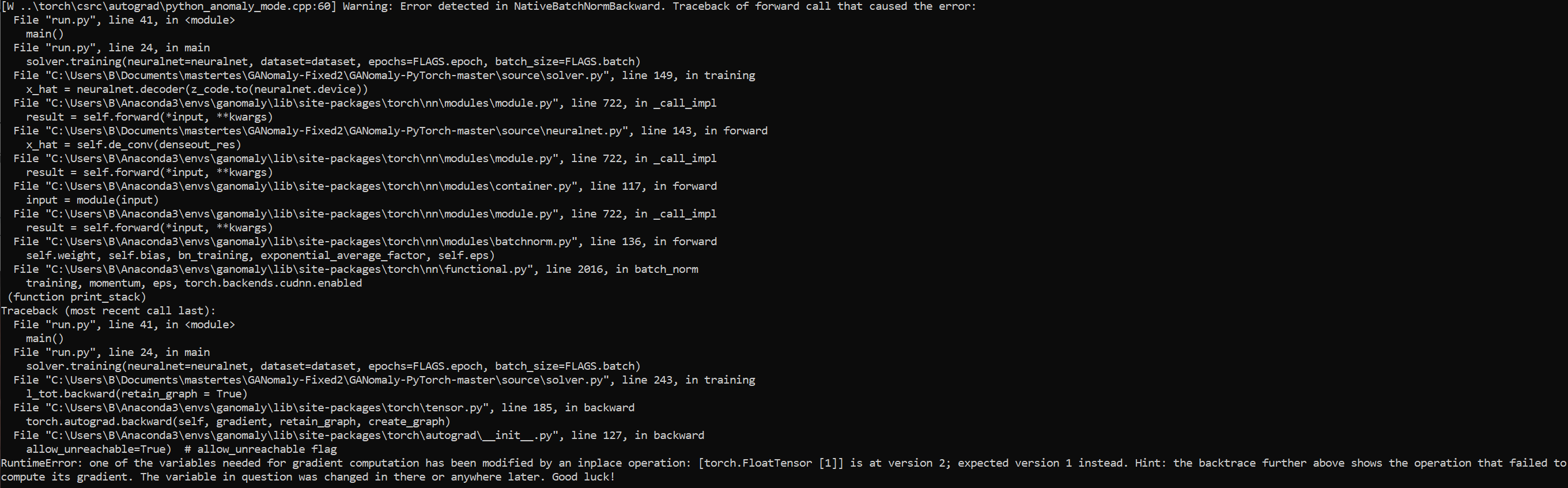
has been modified by an inplace operation: [torch.FloatTensor [1]] is at version 2, expected version 1.
I know that this error implies that the computational graph has been used previously, and one should not use it twice. However - what does “[torch.FloatTensor [1]]” specifiy? And what does “version 2” and “version 1” mean?
My code is quite long but in short:
ref_grad = []
for i in range(2):
layer_grad = utils.AverageMeter()
k = 0
for param in neuralnet.decoder.de_dense.parameters():
if(k == 0 or k == 2):
wrtt = param
print(param.shape)
k = k + 1
layer_grad.avg = torch.zeros(wrtt.shape).to(device)
ref_grad.append(layer_grad)
for j in range(2):
k = 0
for param in neuralnet.encoder.en_dense.parameters():
if(k == 0 or k == 2):
wrt = param
print(param.shape)
k = k + 1
target_grad = torch.autograd.grad(recon_loss, wrt, create_graph = True, retain_graph = True)[0]
print(j)
grad_loss += -1*func.cosine_similarity(target_grad.view(-1,1), ref_grad[j].avg.view(-1,1), dim = 0)
grad_loss = grad_loss/l_2
neuralnet.optimizer.zero_grad()
l_tot.backward(retain_graph = True)
If I remove target_grad and grad_loss, the code is functional (bus useless). So obviously target_grad is the problem here. How do I fix this?