In the forum, the solution to this problem is usually this:
loss1.backward(retain_graph=True)
loss2.backward()
optimizer1.step()
optimizer2.step()
This is indeed a very good method. I did try this solution at the beginning, but later I found that this method does not seem to be suitable for the network I need to implement.
First of all, this is the network I need to implement:
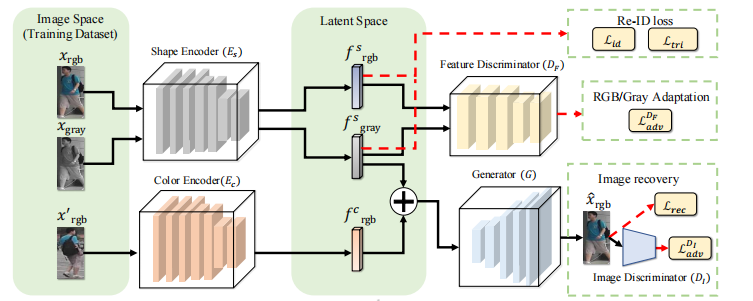
In order to solve this problem, I provide a simplest network implementation:
class EC(nn.Module):
def __init__(self):
super(EC,self).__init__()
self.conv1=nn.Conv2d(3,64,kernel_size=3,stride=2,padding=1)
self.pool=nn.AdaptiveAvgPool2d(1)
def forward(self,x):
x=self.conv1(x)
x=self.pool(x)
x=x.view(x.shape[0],-1)
return x
class ES(nn.Module):
def __init__(self):
super(ES,self).__init__()
self.conv1=nn.Conv2d(3,64,kernel_size=3,stride=2,padding=1)
self.pool=nn.AdaptiveAvgPool2d(1)
self.fc=nn.Linear(64,10)
def forward(self,x):
x=self.conv1(x)
x=self.pool(x)
x=x.view(x.shape[0],-1)
feat=x
x=self.fc(x)
return feat,x
class DF(nn.Module):
def __init__(self):
super(DF,self).__init__()
self.linear=nn.Linear(64,64*128*128)
self.conv1=nn.Conv2d(64,128,kernel_size=3,stride=2,padding=1)
self.pool=nn.AdaptiveAvgPool2d(1)
self.fc=nn.Linear(128,1)
def forward(self,x):
x=self.linear(x)
x=x.view(x.shape[0],64,128,128)
x=self.conv1(x)
x=self.pool(x)
x=x.view(x.shape[0],-1)
x=self.fc(x)
return x
class DI(nn.Module):
def __init__(self):
super(DI,self).__init__()
self.conv1=nn.Conv2d(3,128,kernel_size=3,stride=2,padding=1)
self.pool=nn.AdaptiveAvgPool2d(1)
self.fc=nn.Linear(128,1)
def forward(self,x):
x=self.conv1(x)
x=self.pool(x)
x=x.view(x.shape[0],-1)
x=self.fc(x)
return x
class Gan(nn.Module):
def __init__(self):
super(Gan,self).__init__()
self.linear=nn.Linear(64,64*128*128)
self.conv1=nn.Conv2d(64,3,kernel_size=1)
def forward(self,x):
x=self.linear(x)
x=x.view(x.shape[0],64,128,128)
x=self.conv1(x)
return x
Then the problem lies in the training ideas provided by the author in this paper:

You can see that this training method is similar to gan’s training method, first update the parameters of one part, and then update the other part。
I provide the implementation of these losses, and then for L_df(L_di), DF(DI) is to make L_df(L_di) smaller, and ES(EC) is to make L_df(L_di) bigger,which is similar to gan, so it is different from the paper , I added a gan_loss to train ES(EC) instead of using -1*L_df(-L_di)
class CrossEntropyLabelSmoothLoss(nn.Module):
"""Cross entropy loss with label smoothing regularizer.
Reference:
Szegedy et al. Rethinking the Inception Architecture for Computer Vision. CVPR 2016.
Equation: y = (1 - epsilon) * y + epsilon / K.
Args:
num_classes (int): number of classes.
epsilon (float): weight.
"""
def __init__(self, num_classes, epsilon=0.1, use_gpu=True):
super(CrossEntropyLabelSmoothLoss, self).__init__()
self.num_classes = num_classes
self.epsilon = epsilon
self.use_gpu = use_gpu
self.logsoftmax = nn.LogSoftmax(dim=1)
def forward(self, inputs, targets):
"""
Args:
inputs: prediction matrix (before softmax) with shape (batch_size, num_classes)
targets: ground truth labels with shape (num_classes)
"""
log_probs = self.logsoftmax(inputs)
targets = torch.zeros(log_probs.size()).scatter_(1, targets.unsqueeze(1).cpu(), 1)
if self.use_gpu: targets = targets.cuda()
targets = (1 - self.epsilon) * targets + self.epsilon / self.num_classes
loss = (- targets * log_probs).mean(0).sum()
return loss
from typing import Tuple
from torch import Tensor
def convert_label_to_similarity(normed_feature: Tensor, label: Tensor) -> Tuple[Tensor, Tensor]:
similarity_matrix = normed_feature @ normed_feature.transpose(1, 0)
label_matrix = label.unsqueeze(1) == label.unsqueeze(0)
positive_matrix = label_matrix.triu(diagonal=1)
negative_matrix = label_matrix.logical_not().triu(diagonal=1)
similarity_matrix = similarity_matrix.view(-1)
positive_matrix = positive_matrix.view(-1)
negative_matrix = negative_matrix.view(-1)
return similarity_matrix[positive_matrix], similarity_matrix[negative_matrix]
def normalize(x, axis=-1):
x = 1. * x / (torch.norm(x, 2, axis, keepdim=True).expand_as(x) + 1e-12)
return x
class CircleLoss(nn.Module):
def __init__(self, m: float, gamma: float) -> None:
super(CircleLoss, self).__init__()
self.m = m
self.gamma = gamma
self.soft_plus = nn.Softplus()
def forward(self,feat,label) -> Tensor:
feat=normalize(feat,axis=-1)
sp, sn = convert_label_to_similarity(feat, label)
ap = torch.clamp_min(- sp.detach() + 1 + self.m, min=0.)
an = torch.clamp_min(sn.detach() + self.m, min=0.)
delta_p = 1 - self.m
delta_n = self.m
logit_p = - ap * (sp - delta_p) * self.gamma
logit_n = an * (sn - delta_n) * self.gamma
loss = self.soft_plus(torch.logsumexp(logit_n, dim=0) + torch.logsumexp(logit_p, dim=0))
return loss
cls_criterion=CrossEntropyLabelSmoothLoss(10)
circle_criterion=CircleLoss(m=0.25,gamma=80)
def count_reid_loss(fs_rgb,fs_gray,logit_rgb,logit_gray,label):
loss=0
loss=loss+cls_criterion(logit_gray,label)
loss=loss+cls_criterion(logit_rgb,label)
loss=loss+circle_criterion(fs_gray,label)
loss=loss+circle_criterion(fs_rgb,label)
return loss
def count_d_loss(model,real,fake):
loss=0
out_real=model(real)
out_fake=model(fake)
for out0,out1 in zip(out_real,out_fake):
loss =loss+ torch.mean((out1- 0) ** 2) + torch.mean((out0 - 1) ** 2)
return loss
def count_rec_loss(image,fake_image):
diff=image-fake_image
loss=torch.mean(torch.abs(diff[:]))
return loss
def count_gan_loss(model,x):
out=model(x)
loss=0
for out0 in out:
loss=loss+torch.mean((out0-1)**2)*2
return loss
According to the training steps of the paper, the number of updates is set to 1,this is my simple test code:
device=torch.device('cuda:0')
images=torch.rand(3,3,128,128)
gray_images=torch.rand(3,3,128,128)
other_images=torch.rand(3,3,128,128)
labels=torch.rand(3)
labels=labels.cuda()
labels=labels.long()
images=images.cuda()
gray_images=gray_images.cuda()
other_images=other_images.cuda()
df=DF()
di=DI()
es=ES()
ec=EC()
gan=Gan()
df=df.cuda()
di=di.cuda()
es=es.cuda()
ec=ec.cuda()
gan=gan.cuda()
ES_optimizer=torch.optim.Adam(es.parameters(),0.001)
EC_optimizer=torch.optim.Adam(ec.parameters(),0.001)
DF_optimizer=torch.optim.Adam(df.parameters(),lr=0.001)
DI_optimizer=torch.optim.Adam(di.parameters(),0.001)
G_optimizer=torch.optim.Adam(gan.parameters(),0.001)
fs_rgb,logit_rgb=es(images)
fs_gray,logit_gray=es(gray_images)
fc_other=ec(other_images)
fnew=fs_gray+fc_other
fake_images=gan(fnew)
loss_reid=count_reid_loss(fs_rgb,fs_gray,logit_rgb,logit_gray,labels)
loss_rec=count_rec_loss(images,fake_images)
loss_df_n=count_gan_loss(df,fc_other)
loss_di_n=count_gan_loss(di,fake_images)
loss_df=count_d_loss(df,fs_rgb,fs_gray)
loss_di=count_d_loss(di,images,fake_images)
loss_reid.backward(retain_graph=True)
loss_rec.backward(retain_graph=True)
loss_df_n.backward(retain_graph=True)
loss_di_n.backward(retain_graph=True)
ES_optimizer.step()
EC_optimizer.step()
G_optimizer.step()
DF_optimizer.zero_grad()
DI_optimizer.zero_grad()
loss_df.backward()
DF_optimizer.step()
loss_di.backward()
DI_optimizer.step()
Then the following error appeared:
RuntimeError Traceback (most recent call last)
<ipython-input-13-6ffdf6553113> in <module>()
42 DF_optimizer.zero_grad()
43 DI_optimizer.zero_grad()
---> 44 loss_df.backward()
45 DF_optimizer.step()
46 loss_di.backward()
1 frames
/usr/local/lib/python3.7/dist-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
145 Variable._execution_engine.run_backward(
146 tensors, grad_tensors_, retain_graph, create_graph, inputs,
--> 147 allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
148
149
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [64, 3, 3, 3]] is at version 4; expected version 3 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
But something very strange happened again. If I train with amp, I won’t go wrong in this test:
with autocast():
fs_rgb,logit_rgb=es(images)
fs_gray,logit_gray=es(gray_images)
fc_other=ec(other_images)
fnew=fs_gray+fc_other
fake_images=gan(fnew)
loss_reid=count_reid_loss(fs_rgb,fs_gray,logit_rgb,logit_gray,labels)
loss_rec=count_rec_loss(images,fake_images)
loss_df_n=count_gan_loss(df,fc_other)
loss_di_n=count_gan_loss(di,fake_images)
loss_df=count_d_loss(df,fs_rgb,fs_gray)
loss_di=count_d_loss(di,images,fake_images)
scaler.scale(loss_reid).backward(retain_graph=True)
scaler.scale(loss_rec).backward(retain_graph=True)
scaler.scale(loss_df_n).backward(retain_graph=True)
scaler.scale(loss_di_n).backward(retain_graph=True)
scaler.step(ES_optimizer)
scaler.step(EC_optimizer)
scaler.step(G_optimizer)
DF_optimizer.zero_grad()
DI_optimizer.zero_grad()
scaler.scale(loss_df).backward(retain_graph=True)
scaler.scale(loss_di).backward()
scaler.step(DF_optimizer)
scaler.step(DI_optimizer)
scaler.update()
However, in my complete training code, amp will also go wrong, I don’t know how to solve it!