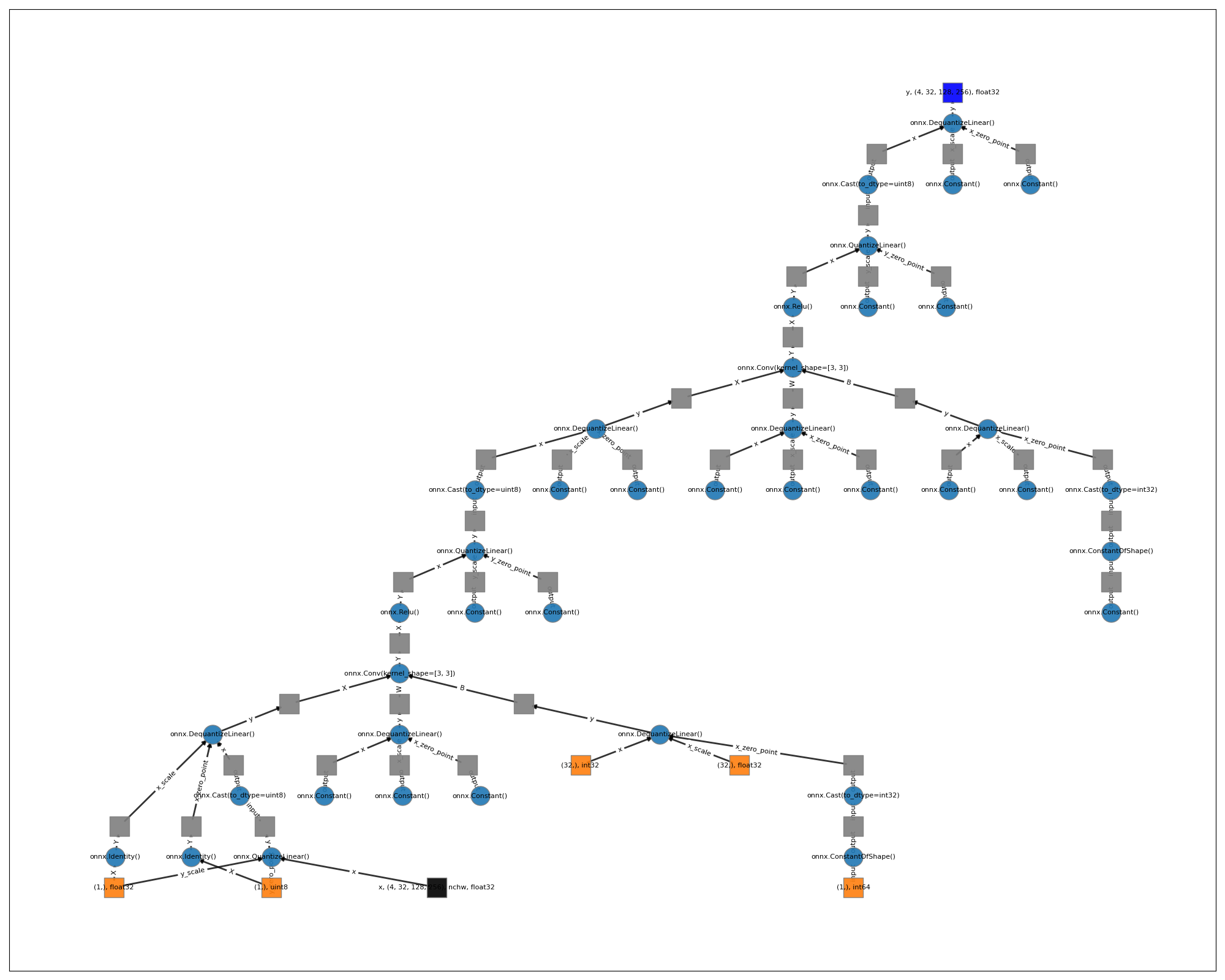
ONNX export fails for many simple quantized models, such as a single Conv2d or Linear layer.
The PyTorch Quantization FAQ suggests creating an issue with the ONNX project on github, but that sounds dubious. In fact, one such recent issue was closed with the comment “Please open this issue in the PyTorch repository.”
It also suggests contacting people from the ONNX exporter maintainers list, which I have done. I have not yet received a reply, which is not surprising.
So I am posting the issue here since it seems like the proper forum.
Here is a simple test that reproduces the errors in PyTorch 2.1. The tests marked with “BUG” are broken and the error message is documented. The other tests pass.
For the issue to be resolved, we would need to modify these tests and the PyTorch source so that the tests pass.
"""Tests that illustrate bugs in PyTorch's ONNX export of quantized models."""
import unittest
from functools import partial
import torch
import torch.nn as nn
from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx, fuse_fx
class _BaseTest(unittest.TestCase):
CHS_IN = 32
CHS_OUT = 64
HEIGHT = 8
WIDTH = 16
BATCH_SIZE = 4
KERNELS_SIZE = 3
PADDING = 1
def _onnx_export(self, file_name="real.onnx"):
"""Test ONNX export."""
_export_to_onnx(model=self.model, x=self.x, file_name=file_name)
def _onnx_export_quantized(self, file_name="quantized.onnx"):
"""Test ONNX export of a quantized model."""
corpus = _get_random_corpus(self.x)
batch_size = self.x.shape[0]
quantized_model = _static_quantize_model(
model=self.model, corpus=corpus, batch_size=batch_size
)
_export_to_onnx(model=quantized_model, x=self.x, file_name=file_name)
class TestOnnxExportLinear(_BaseTest):
"""Test cases for exporting a linear layer."""
def setUp(self):
self.model = nn.Linear(self.CHS_IN, self.CHS_OUT)
self.x = torch.rand(self.BATCH_SIZE, self.CHS_IN)
def test_onnx_export_linear(self):
self._onnx_export()
def test_onnx_export_linear_quantized(self):
"""BUG
File "/home/andrew/.local/lib/python3.8/site-packages/torch/jit/_trace.py", line 76, in _unique_state_dict
filtered_dict[k] = v.detach()
AttributeError: __torch__.torch.classes.quantized.LinearPackedParamsBase (of Python compilation unit at: 0) does not have a field with name 'detach'
"""
self._onnx_export_quantized()
class TestOnnxExportLinearRelu(_BaseTest):
"""Test cases for exporting a linear layer followed by ReLU."""
def setUp(self):
self.model = nn.Sequential(nn.Linear(self.CHS_IN, self.CHS_OUT), nn.ReLU())
self.x = torch.rand(self.BATCH_SIZE, self.CHS_IN)
def test_onnx_export_linear_relu(self):
self._onnx_export()
def test_onnx_export_linear_relu_quantized(self):
"""BUG
File "/home/andrew/.local/lib/python3.8/site-packages/torch/onnx/utils.py", line 1950, in _run_symbolic_function
raise errors.UnsupportedOperatorError(
torch.onnx.errors.UnsupportedOperatorError: Exporting the operator 'quantized::linear_relu' to ONNX opset version 17 is not supported. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues.
"""
self._onnx_export_quantized()
class TestOnnxExportConv2d(_BaseTest):
"""Test cases for exporting a conv2d layer."""
def setUp(self):
self.model = nn.Conv2d(
self.CHS_IN, self.CHS_OUT, self.KERNELS_SIZE, padding=self.PADDING
)
self.x = torch.rand(self.BATCH_SIZE, self.CHS_IN, self.HEIGHT, self.WIDTH)
def test_onnx_export_conv2d(self):
self._onnx_export()
def test_onnx_export_conv2d_quantized(self):
"""BUG
File "/home/andrew/.local/lib/python3.8/site-packages/torch/jit/_trace.py", line 76, in _unique_state_dict
filtered_dict[k] = v.detach()
AttributeError: __torch__.torch.classes.quantized.Conv2dPackedParamsBase (of Python compilation unit at: 0) does not have a field with name 'detach'
"""
self._onnx_export_quantized()
class TestOnnxExportConv2dRelu(_BaseTest):
"""Test cases for exporting a conv2d layer followed by ReLU."""
def setUp(self):
"""Setup the model and dummy input."""
self.model = nn.Sequential(
nn.Conv2d(
self.CHS_IN, self.CHS_OUT, self.KERNELS_SIZE, padding=self.PADDING
),
nn.ReLU(),
)
self.x = torch.rand(self.BATCH_SIZE, self.CHS_IN, self.HEIGHT, self.WIDTH)
def test_onnx_export_conv2d_relu(self):
self._onnx_export()
def test_onnx_export_conv2d_relu_quantized(self):
self._onnx_export_quantized()
def _export_to_onnx(
model=None,
x=None,
input_names=["input"],
output_names=["output"],
file_name="my_onnx_file.onnx",
):
"""Exports a model to an ONNX file."""
model.eval()
torch.onnx.export(
model,
x,
file_name,
export_params=True,
input_names=input_names,
output_names=output_names,
)
def _get_random_corpus(dummy_input, corpus_size=64):
"""Returns a random tensor representing a quantization corpus."""
batch_size, *input_shape = dummy_input.shape
corpus_shape = (corpus_size, *input_shape)
return torch.rand(*corpus_shape)
def _static_quantize_model(model=None, corpus=None, batch_size=None):
"""Returns a model created from static quantization of the given model.
Applies post-training static quantization, using per-channel symmetric
quantization for weights and per-tensor affine quantization of activations.
"""
activations_observer = partial(
torch.ao.quantization.observer.HistogramObserver,
qscheme=torch.per_tensor_affine,
dtype=torch.quint8,
)
weights_observer = partial(
torch.ao.quantization.observer.PerChannelMinMaxObserver,
qscheme=torch.per_channel_symmetric,
dtype=torch.qint8,
)
my_qconfig = torch.ao.quantization.QConfig(
activation=activations_observer, weight=weights_observer
)
qconfig_mapping = torch.ao.quantization.QConfigMapping().set_global(my_qconfig)
dataset = torch.utils.data.TensorDataset(corpus)
data_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size)
model.eval()
first_input = (next(iter(data_loader))[0],)
prepared_model = prepare_fx(model, qconfig_mapping, first_input)
_calibrate(prepared_model, data_loader)
quantized_model = convert_fx(prepared_model)
return quantized_model
def _calibrate(model, data_loader):
"""Runs all inputs in the data-loader through the model.
This function can be used to calibrate static quantization parameters.
"""
with torch.no_grad():
for (x,) in data_loader:
model(x)
if __name__ == "__main__":
unittest.main()