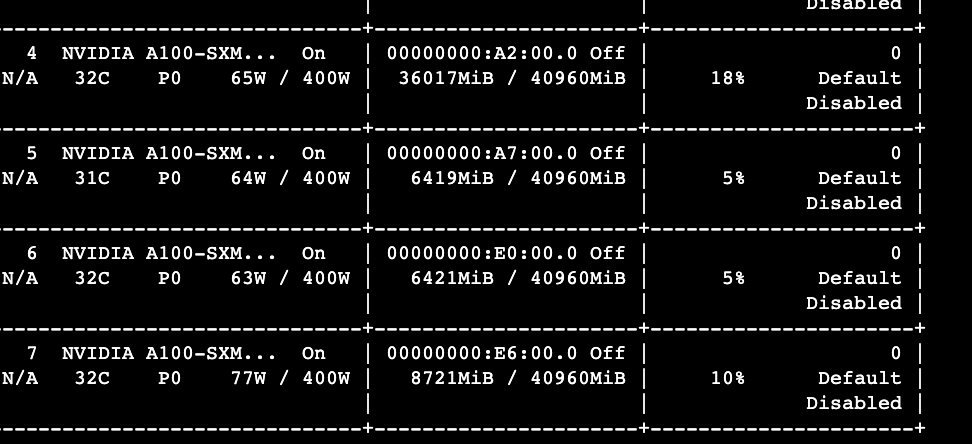
I have a Weriod OOM problem when I use 2 gpu like CUDA_VISIBLE_DEVICES=4,5.
But, when I use CUDA_VISIBLE_DEVICES =4,5,6,7, it seems to work well. And I check the memory usage like this below, which showed that the total usage of gpu 4,5,6,7 is less than 40G*2=80G.
Does this mean that I can use 2 gpu like CUDA_VISIBLE_DEVICES=4,5 to work well ?
By the way, I also don’t understand why the memory allocated is not in an average for each gpu in the picture. Maybe it is the machanism of pytorch?
Thanks for your help in advance!
It’s unclear what your use case is and what’s causing the OOM.
PyTorch’s DDP will create a balanced memory usage assuming you are using the same local batch size while the legacy DP approach uses an imbalanced memory usage and is thus not recommended (besides also increasing the communication need).
1 Like
Thanks for your prompt reply, and sorry for missing some necessary details!
I did not use either DDP or DP. And my case is only doing LLM inference and concretely, I load 3 models to do inference on each sample(for my special case, I can’t sequentially load each model and do it sequentially).
The purpose of using “CUDA_VISIBLE_DEVICES=4,5” to include multiple GPUs is to avoid OOM when loading 3 models in the same time.
Did I have a correct usage of “CUDA_VISIBLE_DEVICES=4,5”? Or what is the best practice for achieving the purpose of loading multiple models without OOM when I have a few 40g gpus but no 80g gpus?
Thanks for your advice in advance! 
model1 = AutoModelForCausalLM.from_pretrained(
model_path,
load_in_8bit=True,
torch_dtype=torch.float16,
device_map="auto"
)
model2 = ...
model3 = ...
Thanks anyway, I have solved the problem. We should set device_map to auto instead of gpu.