I am trying to fine-tune a model on my machine, I have prepared my dataset images of 256*256. However, once I load the checkpoints file, I get the error shown below. Ps: I used the same file to test and it is working, I can retrain the model from epoch 0 normal and I don’t need to make any changes.
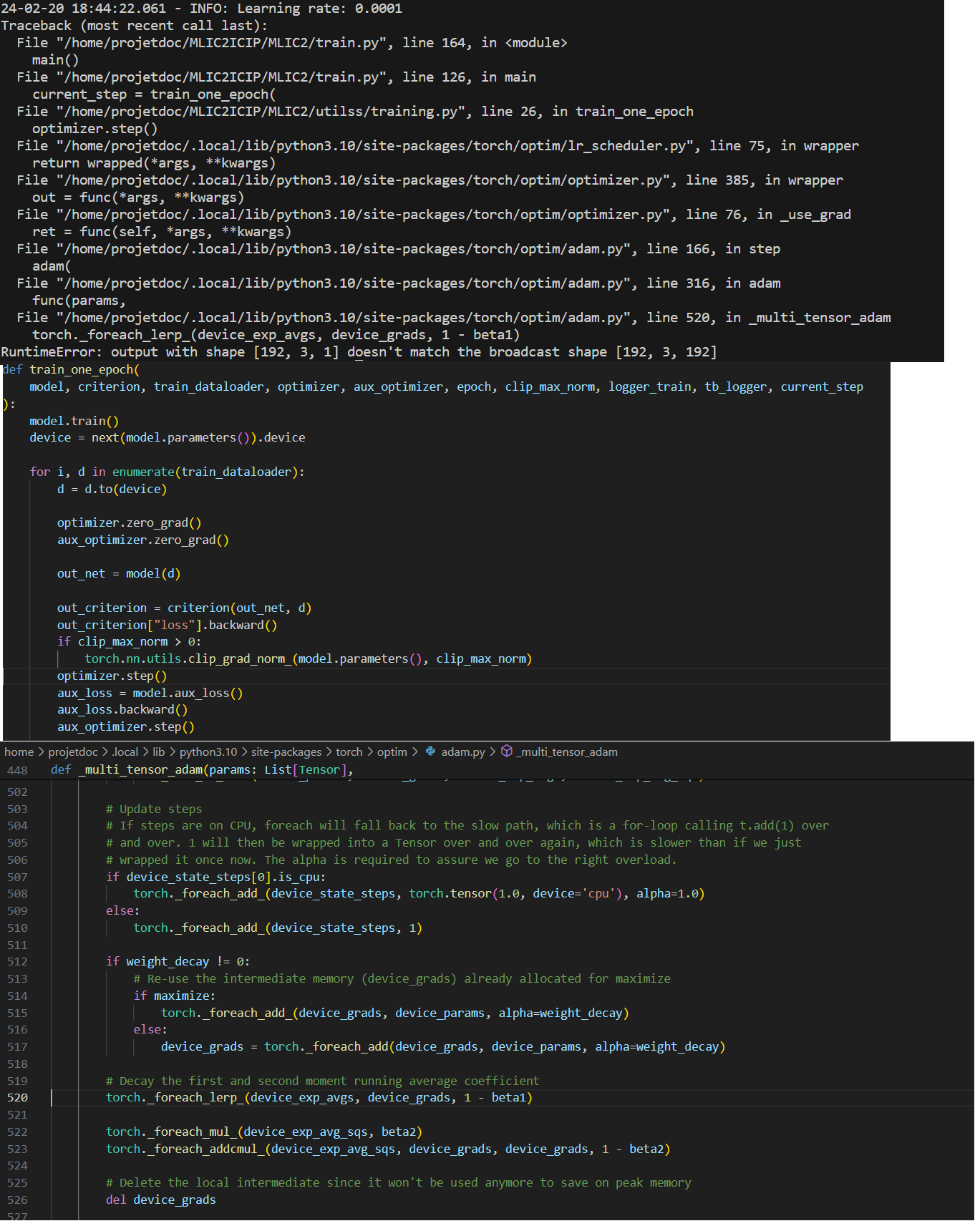
Could you post a minimal and executable code snippet to reproduce the issue?
1 Like
of course here you are. here some more details. I am using wsl ubuntu 22.04, and I am using the compressai lib. The first time, after installation, it’s worked perfectly, however I had to chmod the home repository because a warning about no permission to write and it worked.
You need to copy and paste in the code and wrap it in three backticks ```, posting screenshots doesn’t work.
1 Like
import torch
import torch.nn as nn
import torch.optim as optim
load the dataset, split into input (X) and output (y) variables
dataset = np.loadtxt(‘pima-indians-diabetes.csv’, delimiter=‘,’)
X = dataset[:,0:8]
y = dataset[:,8]
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.float32).reshape(-1, 1)
model = nn.Sequential(
nn.Linear(8, 12),
nn.ReLU(),
nn.Linear(12, 8),
nn.ReLU(),
nn.Linear(8, 1),
nn.Sigmoid()
)
loss_fn = nn.BCELoss() # binary cross entropy
optimizer = optim.Adam(model.parameters(), lr=0.001)
n_epochs = 100
batch_size = 10
for epoch in range(n_epochs):
for i in range(0, len(X), batch_size):
Xbatch = X[i:i+batch_size]
y_pred = model(Xbatch)
ybatch = y[i:i+batch_size]
loss = loss_fn(y_pred, ybatch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f’Finished epoch {epoch}, latest loss {loss}')
Your code is not executable as it depends on specific data. It’s also not formatted properly and does not load a checkpoint, which seems to trigger the error.
1 Like
alright, thank you. and this case:
net = MLICPlusPlus(config=config)
if args.cuda and torch.cuda.device_count() > 1:
net = CustomDataParallel(net)
net = net.to(device)
#optimizer, aux_optimizer = configure_optimizers(net, args)
parameters = set(p for n, p in net.named_parameters() if not n.endswith(".quantiles"))
aux_parameters = [p for n, p in net.named_parameters() if n.endswith(".quantiles")]
optimizer = optim.Adam(parameters, lr=1e-4)
aux_optimizer = optim.Adam(aux_parameters, lr=1e-3)
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[80, 100], gamma=0.1)
criterion = RateDistortionLoss(lmbda=args.lmbda, metrics=args.metrics)
if args.checkpoint != None:
checkpoint = torch.load(args.checkpoint)
# new_ckpt = modify_checkpoint(checkpoint['state_dict'])
net.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
aux_optimizer.load_state_dict(checkpoint['aux_optimizer'])
# lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[450,550], gamma=0.1)
# lr_scheduler._step_count = checkpoint['lr_scheduler']['_step_count']
# lr_scheduler.last_epoch = checkpoint['lr_scheduler']['last_epoch']
# print(lr_scheduler.state_dict())
start_epoch = checkpoint['epoch']
best_loss = checkpoint['loss']
current_step = start_epoch * math.ceil(len(train_dataloader.dataset) / args.batch_size)
checkpoint = None
else:
start_epoch = 0
best_loss = 1e10
current_step = 0
# start_epoch = 0
# best_loss = 1e10
# current_step = 0
logger_train.info(args)
logger_train.info(config)
logger_train.info(net)
logger_train.info(optimizer)
optimizer.param_groups[0]['lr'] = args.learning_rate
for epoch in range(start_epoch, args.epochs):
logger_train.info(f"Learning rate: {optimizer.param_groups[0]['lr']}")
current_step = train_one_epoch(
net,
criterion,
train_dataloader,
optimizer,
aux_optimizer,
epoch,
args.clip_max_norm,
logger_train,
tb_logger,
current_step
)
save_dir = os.path.join('./experiments', args.experiment, 'val_images', '%03d' % (epoch + 1))
loss = test_one_epoch(epoch, test_dataloader, net, criterion, save_dir, logger_val, tb_logger)
lr_scheduler.step()
is_best = loss < best_loss
best_loss = min(loss, best_loss)
net.update(force=True)
if args.save:
save_checkpoint(
{
"epoch": epoch + 1,
"state_dict": net.state_dict(),
"loss": loss,
"optimizer": optimizer.state_dict(),
"aux_optimizer": aux_optimizer.state_dict(),
"lr_scheduler": lr_scheduler.state_dict(),
},
is_best,
os.path.join('./experiments', args.experiment, 'checkpoints', "checkpoint_%03d.pth.tar" % (epoch + 1))
)
if is_best:
logger_val.info('best checkpoint saved.')