I wrote the following short pytorch code. The program runs fine but the optimizer seems to just completely ignore the loss.
import torch
from torch import Tensor, nn
from torch.optim import AdamW
num_bars = 3000
num_symbols = 500
days = torch.linspace(0, num_symbols, num_bars)
max_val = torch.tensor([num_symbols])
class MyModel(nn.Module):
def __init__(self) -> None:
super().__init__()
self.log_threshold = nn.Parameter(
torch.tensor([num_symbols * 0.95]).log(),
)
def forward(self, x: Tensor) -> Tensor:
thresholds = torch.cat([self.log_threshold.exp(), max_val])
nearest_larger_threshold = thresholds[
(thresholds >= x.unsqueeze(1)).int().argmax(dim=1)
]
return nearest_larger_threshold
model = MyModel()
optimizer = AdamW(model.parameters(), lr=0.0001)
def loss_fn(x: Tensor) -> Tensor:
return x.square().sum()
for _ in range(30000):
optimizer.zero_grad()
output: Tensor = model(days)
loss = loss_fn(output)
loss.backward()
optimizer.step()
print(f"Loss: {loss.item()}")
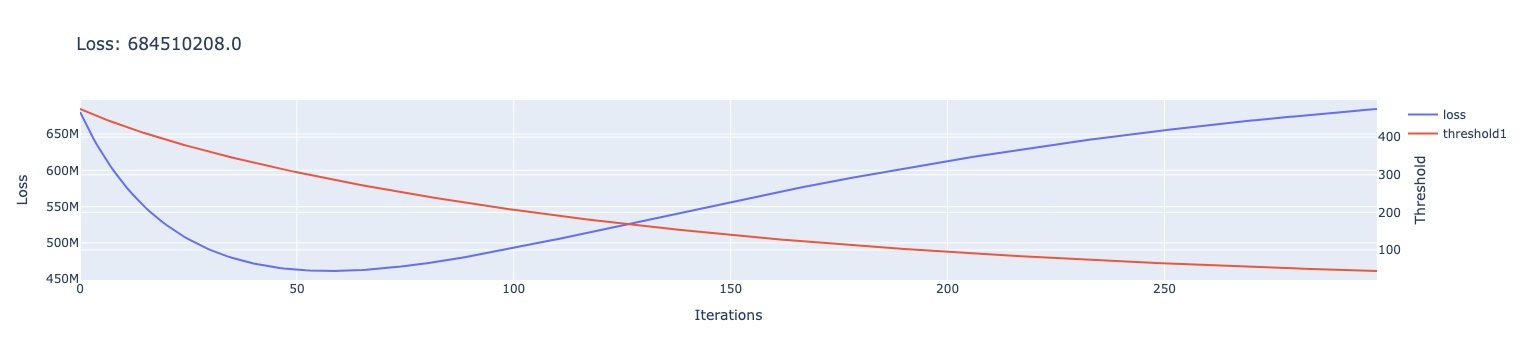
Here’s a plot I made of the loss and threshold. It’s clear that the optimizer is just lowering the log threshold at every step, regardless of the loss.
Here’s the logic behind the nearest_larger_threshold code:
x = torch.tensor([1.2, 3.4, 5.6, 7.8, 9.0])
thresholds = torch.tensor([4, 6, 9])
# I want to get the nearest larger threshold for each value in x
# Desired output: tensor([4, 4, 6, 9, 9])
foo = thresholds >= x.unsqueeze(1)
print(foo)
# tensor([[ True, True, True],
# [ True, True, True],
# [False, True, True],
# [False, False, True],
# [False, False, True]])
foo = foo.int()
print(foo)
# tensor([[1, 1, 1],
# [1, 1, 1],
# [0, 1, 1],
# [0, 0, 1],
# [0, 0, 1]], dtype=torch.int32)
foo = foo.argmax(dim=1)
print(foo)
# tensor([0, 0, 1, 2, 2])
foo = thresholds[foo]
print(foo)
# tensor([4, 4, 6, 9, 9])
# Correct output! Works as long as the thresholds are sorted