@ptrblck many thanks for your answer, really appreciate you took time for this. I am using the torch.optim.lr_scheduler.OneCycleLR scheduler (torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=1e-3, steps_per_epoch=len(train_dl), epochs=epochs)) and at the beginning of the training the learning rate might be very small. The actual learning rate curve looks like this:
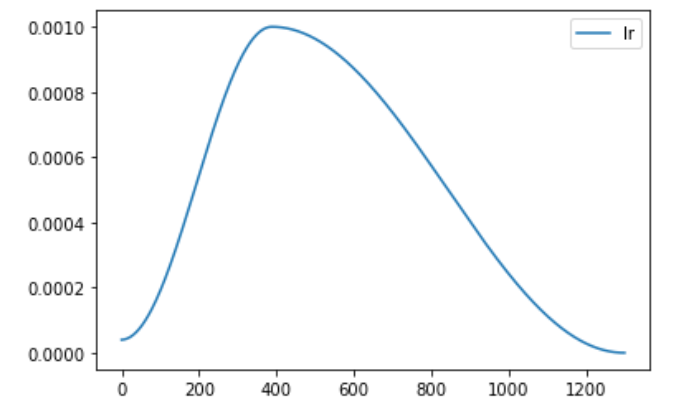
So could it be that because the learning rate is very small at the first iteration, that this is causing this NaN gradients?