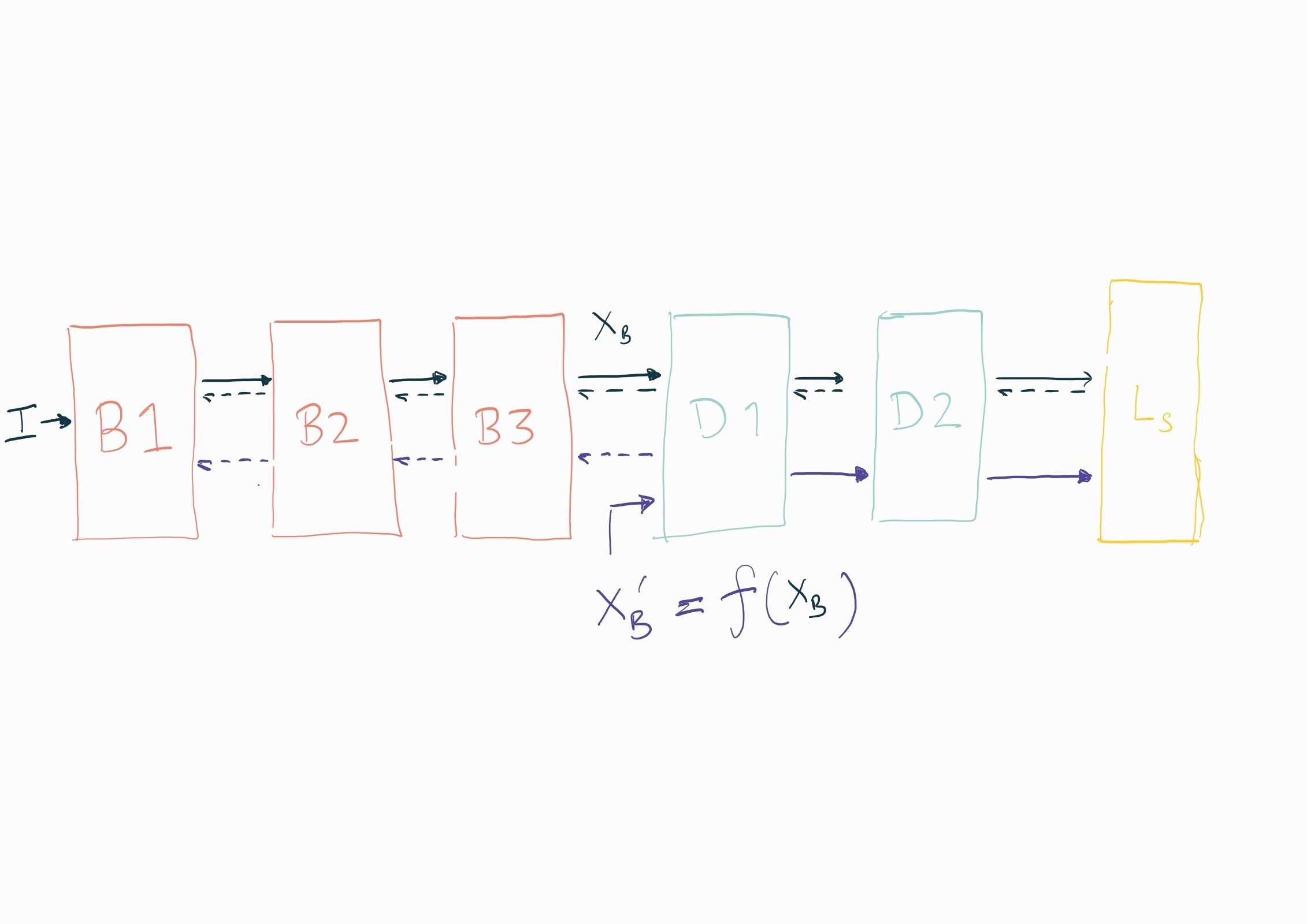
I’m trying to train a model that’s composed of two submodules, B and D, on input I.
Let X_b be the intermediate feature vectors after applying B to I. (X_b = B(I))
Now, D is applied on X_b to get the prediction, on which loss L_s is computed.
What I’m trying to do is as follows:
Step 1: do the above-mentioned forward pass through the entire model, get the loss and propagate gradients backward throughout both B and D.
Step 2: Apply a augmentation/permutation f() on X_b to get X_b’, do a forward call on the submodule D with X_b’ and compute the same loss, but only update either B or D.
I’m attaching an outline sketch of the process. Solid lines of the same colour represent a forward, and dashed lines represent backward gradient updates.
What is the best way to achieve this? I’ve tried quite a few things, including trying to set requires_grad=False for submodule D after the Step 1, but all permutations of things I have tried end up not updating the weights of D at all.
You don’t use the word “optimize” in your description, but I assume that you
want to backpropagate the loss L_s in order to populate the gradients of B
and D and then take an optimization step.
You make the logic a little more complicated by saying in Step 2 that you
want to only update either B or D.
Let’s start with the case where you update D in Step 2:
Perform your Step 1 forward pass, computing L_s and keeping a reference
to X_b. Make a copy of X_b, X_c = X_b.detach().clone(), pass f (X_c)
through D, and compute a second value for the loss L_s. Sum the two
losses together and backpropagate.
The will populate B with gradients due to the Step 1 forward pass and will
populate D with the sum of its Step 1 and Step 2 forward-pass gradients.
You can now optimize with opt_B.step() and opt_D.step().
For the case where you update B in Step 2:
Perform the forward pass just through B. Keep a reference to X_b Pass f (X_b) through D (no .detach() nor .clone()) and compute L_s. Call L_s (retain_graph = True). This populates B with its Step 2 gradients.
(It also populates D with undesired gradients.)
Now call opt_D.zero_grad(). This zeros out the Step 2 gradients for D
that you said you didn’t want. Complete the Step 1 forward pass by passing X_b (to which you kept a reference) through D, compute L_s, and call L_s.backward(). This populates D’s Step 1 gradients and accumulates
B’s Step 1 gradients onto its Step 2 gradients.