import gc
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
torch.set_printoptions(sci_mode=False)
gradient_norms = []
losses = []
for epoch in tqdm(range(epochs)):
model_path = f"/kaggle/working/Training/ace_state_dict_{epoch+1}.pth"
torch.save(model.state_dict(), model_path)
model.train()
total_loss = 0
for batch_idx, batch in enumerate(tqdm(train_dataloader, desc=f'Epoch {epoch + 1}/{epochs}')):
optimizer.zero_grad()
logits = model(batch["inputs"])
targets = batch["targets"]
loss = loss_fn(logits.view(-1, logits.size(-1)), targets.float()) / 1000000000
loss.backward()
# Compute gradient norms
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), 1)
gradient_norms.append(grad_norm)
optimizer.step()
scheduler.step()
total_loss += loss.item()
if batch_idx % 100 == 0:
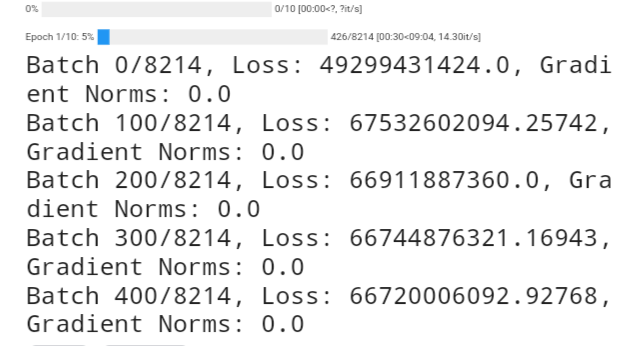
print(f'Batch {batch_idx}/{len(train_dataloader)}, Loss: {total_loss/(batch_idx+1)}, Gradient Norms: {grad_norm}')
avg_loss = total_loss / len(train_dataloader)
losses.append(avg_loss)
print(f"Train loss: {avg_loss}")
In my code above, the “loss.backward()” function is not working as expected, resulting in a “grad_norm” consistently registering as “0.0”. This impedes the optimization of the model’s parameters during each iteration. Any guidance or suggestions to rectify this matter would be greatly appreciated. For reference, you can find the full source code of my model at:
I’ve experimented with various combinations of hyperparameters and learning rates, but unfortunately, the issue persists. Additionally, I attempted to address it by employing “torch.nn.utils.clip_grad_norm_()”, but to no avail. All the relevant tensors and the model’s parameters are set with “requires_grad=True”. Any insights or alternative approaches to resolve this