The code is below.
import torch
from torch import nn
import torch.distributed as dist
import torch.multiprocessing as mp
import os
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.attr1 = nn.Parameter(torch.tensor([1., 2., 3.]))
self.register_buffer('attr2', torch.tensor([4., 5., 6.]))
self.attr3 = torch.tensor([7., 8., 9.])
def forward(self, x, rank):
hd = x * self.attr1
self.attr2 = self.attr2 / (rank + 1)
hd = hd * self.attr2
self.attr3 = self.attr3.to(rank)
self.attr3 = self.attr3 / (rank + 1)
y = hd * self.attr3
y = y.mean()
return y
def run(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group('nccl', rank=rank, world_size=world_size)
# torch.cuda.set_device(rank)
os.environ['CUDA_VISIBLE_DEVICES'] = f'{rank}'
my_model = MyModel().to(rank)
my_model = nn.parallel.DistributedDataParallel(my_model, device_ids=[rank], output_device=rank)
optimizer = torch.optim.SGD(my_model.parameters(), lr=0.001, momentum=0.9)
input = torch.tensor([1., 2., 3.]) * (rank + 1)
optimizer.zero_grad()
output = my_model(input, rank)
output.backward()
if rank == 0:
print(my_model.module.attr1.grad)
optimizer.step()
if rank == 0:
print(my_model.module.attr1)
print(my_model.module.attr2)
print(my_model.module.attr3)
if __name__ == '__main__':
world_size = 2
mp.spawn(run, args=(world_size, ), nprocs=2)
print('执行完毕')
Initially, I write this code in order to see the synchronization mechanism of parameter and buffer in multi GPU training.
Finally, I find torch.cuda.set_device(rank) work well, but os.environ['CUDA_VISIBLE_DEVICES'] not work well. The latter will report an error.
The error information is below.
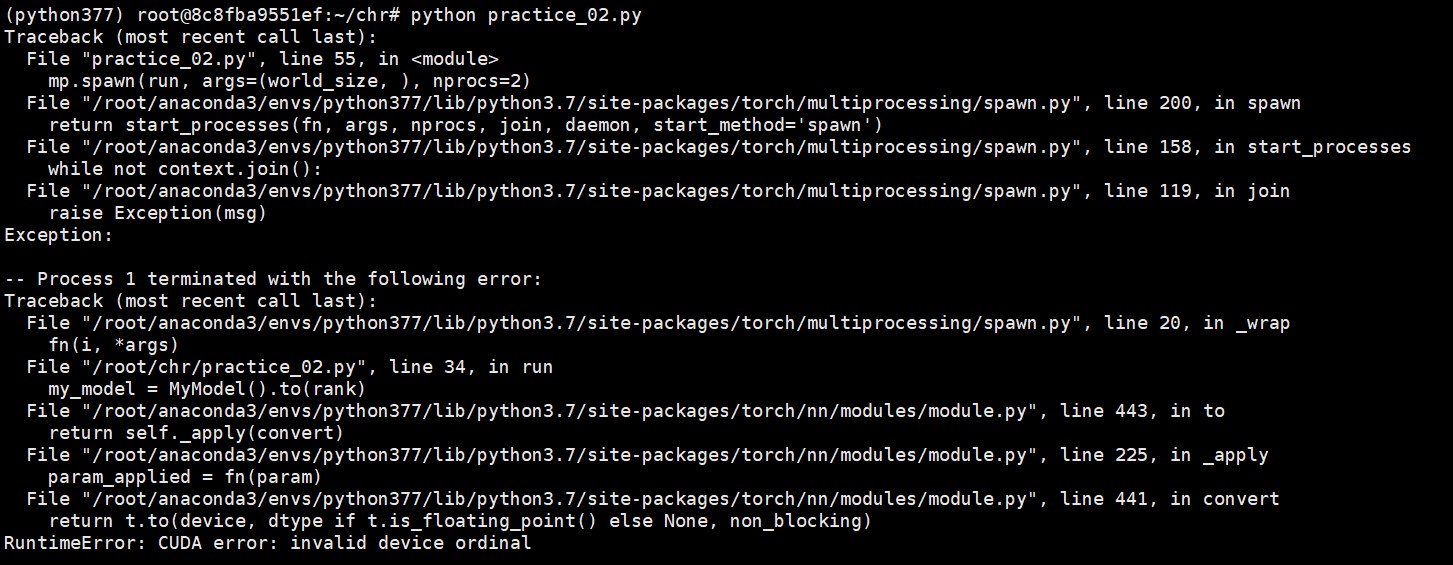
Hope someone can tell me why.

