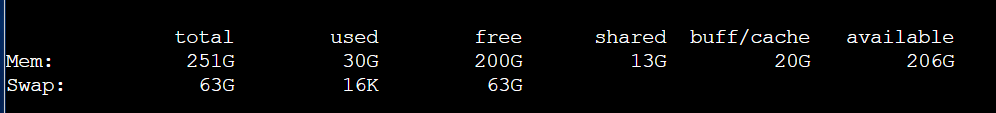Hi,everyone
I run my code on a node with 8 GPUs. I have several observations below.
num_worker = 32 for both training loader and testing loader. In first epoch, it’s fine during training, but the error occurs during testing after the epoch.
num_worker = 64 for both training loader and testing loader. Got the same results as (1).
64 and 8 for training loader and testing loader respectively. First epoch is fine, but the error occurs in the training of next epoch.
32 and 8 for training loader and testing loader respectively. Got the same results as (3).
num_worker = 16 for both training loader and testing loader. Everything is fine.
cat /proc/sys/kernel/pid_max: 32768;
memory usage is shown below with num_worker = 32 for both training loader and testing loader.
Traceback (most recent call last):
File "train.py", line 225, in <module>
trainer.train()
File "train.py", line 164, in train
acc = self.evaluate(epoch)
File "train.py", line 198, in evaluate
for idx, (img, label) in enumerate(self.loader_test):
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 819, in __iter__
return _DataLoaderIter(self)
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 560, in __init__
w.start()
File "/opt/conda/lib/python3.7/multiprocessing/process.py", line 112, in start
self._popen = self._Popen(self)
File "/opt/conda/lib/python3.7/multiprocessing/context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "/opt/conda/lib/python3.7/multiprocessing/context.py", line 277, in _Popen
return Popen(process_obj)
File "/opt/conda/lib/python3.7/multiprocessing/popen_fork.py", line 20, in __init__
self._launch(process_obj)
File "/opt/conda/lib/python3.7/multiprocessing/popen_fork.py", line 70, in _launch
self.pid = os.fork()
OSError: [Errno 12] Cannot allocate memory
knowing that smaller batches run just fine it shows that you just run out of memory!
what is your model? how many parameters does it have?
you can calculate the amount of memory used by your model and just multiply that by the threads .
for example for the input you have :
256x(224x224x3) x 4 / 1024^2 = 147MB
assuming you are using float32. So 32 threads each reading 256 images, will take 4,704 MB. and this is only the input batch, you need to calculate how much memory your model takes and take that into account as well.
if you want you can use torchstat and get such info and then choose the best course of action.
also recall that in training phase the memory usage is 2~3 times more than what you calculate for your number of parameters since you need to take into account the gradients and optimizes states as well.
Thank you for your reply,
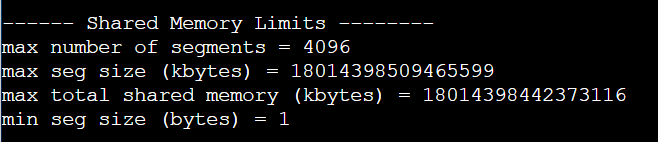
The share memory limits are extremely large. I feel like it’s very strange. I run my code in an AI platform, and the outputs of ipcs -lm before and after logging to a node are the same. I’m not familiar with the use of the platform.
Is this information about shared memory accurate?
Can you see anything meaningful in it?
Thank your for your analysis,
From my perspective, given the error occurs in Dataloader, it’s not related to the size of model. It’s a matter of CPU memory instead of GPU memory. And the information of memory usage shows that memory is adequate.
Have I got it wrong?
If I recall correctly, the data is first cached in your system RAM, and then when your model signals for new data, it is transferred to the GPU memory and there you go.
I guess either this is the case, or you have memory leak. if its memory leak, you should be able to tell by monitoring the memory usage during a time frame in your training.
I once faced memory leak, during long training session, memory was exhausted and ultimately I’d get a out of memory error!
i think Starting by checking the vmsize of the process that failed to fork, at the time of the fork attempt, and then compare to the amount of free memory (physical and swap) as it relates to the overcommit policy (plug the numbers in.)