Hello,
I’m working on semantic segmentation project on pytorch framework. I wrote example code for UNet model with n_classes=1 and run it on windows 10 PC. Everything was great but get a lot of time because of poor gpu. Env was created via conda:
python = 3.6.6
PIL=5.4.1
pytorch=1.0.1
So, i gone to dedicated server with 1080 ti ubuntu 18.04 lts. Created the same env and checked package versions - all right. After that i moved source code and dataset to dedicated server and run it. But after first epoch i get following exception:
https://hastebin.com/medolataxa.sql
OSError: image file is truncated (28 bytes not processed)
I haven’t use truncated files. Everything was okay on windows 10, but after first epoch everything collapsed. (p.s. use allow truncated_files doesn’t solve the issue).
It is also strange, that PIL.Image.open(<image_path>) recursive running on dataset didn’t throw any exception with files on dedicated server.
Is someone know how to fix it?
Maybe there were some issues moving these files to the server?
Could you try to load all images in a loop, store the index which gives you the error, and have a look at this particular file?
Something like this should give you the index:
for idx, (data, target) in enumerate(dataset):
print(idx)
The error should then be related to idx+1. Depending on the Dataset you are using, you could try to get the corresponding image path and check the file manually.
Thank you @ptrblck for yor reply,
I wrote custom Dataset. Here is a code:
class DatasetLoader(Dataset):
def __init__(self, X, y, input_transform=None, label_transform=None):
self.data = X
self.labels = y
self.input_transform = input_transform
self.label_transform = label_transform
@staticmethod
def load_dataset(data_dir: str):
logger.debug(f"load_dataset: Loading dataset from {data_dir}")
inputs_dir = f'{data_dir}/inputs'
labels_dir = f'{data_dir}/labels'
inputs = []
for image_path in tqdm(glob.glob(inputs_dir + '/*')):
image = Image.open(image_path)
inputs.append(image)
labels = []
for image_path in tqdm(glob.glob(labels_dir + '/*')):
label = Image.open(image_path).convert('L')
labels.append(label)
return inputs, labels
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
data = self.data[idx]
if self.input_transform is not None:
data = self.input_transform(data)
label = self.labels[idx]
if self.label_transform is not None:
label = self.label_transform(label)
return data, label
Also i zipped dataset folder, moved to dedicated server via scp and check sha256sum. Everything was good.
Thanks for the code!
You could add a try ... expect block around the loop where Image.open is called and see, which image makes problems.
Maybe you are using different PIL versions, such that this issue was fixed on your local machine?
Actually, image loading works good. I checked it in jupyter. Also, code using shown below:
def load_datasets(data_dir, input_size, test_pct=0.2, eval_size=10):
train_transform, test_transform, label_transform = create_transforms(input_size)
X, y = DatasetLoader.load_dataset(data_dir)
train_slice = round((1 - test_pct) * len(X))
train_data = DatasetLoader(X[:train_slice], y[:train_slice],
input_transform=train_transform, label_transform=label_transform)
test_data = DatasetLoader(X[train_slice:], y[train_slice:],
input_transform=test_transform, label_transform=label_transform)
eval_data = DatasetLoader(X[-eval_size:], y[-eval_size:],
input_transform=test_transform, label_transform=label_transform)
logger.debug(f"load_datasets: (train_data, test_data, eval_data) sizes = "
f"{len(train_data), len(test_data), len(eval_data)}")
return train_data, test_data, eval_data
So, images get loaded before iteration within trainloader
The error message point to PIL.ImageFile.load, which is weird if image loading is not an issue.
Could you create a (small) code snippet to reproduce this error?
Wait a minute, i’ll provide sample code for train and exact line where exception throws from.
Here is my sample code for training:
with tensorboardX.SummaryWriter(log_dir=log_dir) as summary_writer:
for epoch in range(epochs):
epoch_train_loss = 0
model.train()
logger.debug(f"train: Running epoch {epoch + 1} out of {epochs}")
for inputs, labels in tqdm(trainloader):
inputs, labels = inputs.cuda(non_blocking=True), labels.cuda(non_blocking=True)
outputs = model.forward(inputs)
loss = criterion(outputs, labels)
epoch_train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
Also some utils:
def create_transforms(input_size):
channel_means = [0.485, 0.456, 0.406]
channel_stds = [0.229, 0.224, 0.225]
train_tfms = transforms.Compose([transforms.Resize(input_size),
transforms.ToTensor(),
transforms.Normalize(channel_means, channel_stds)])
test_tfms = transforms.Compose([transforms.Resize(input_size),
transforms.ToTensor(),
transforms.Normalize(channel_means, channel_stds)])
mask_tfms = transforms.Compose([transforms.Resize(input_size),
transforms.ToTensor()])
return train_tfms, test_tfms, mask_tfms
def create_dataloaders(data_dir, input_size=256, test_pct=0.2, batch_size=64) -> (DataLoader, DataLoader, DataLoader):
train_data, test_data, eval_data = load_datasets(data_dir, input_size, test_pct)
trainloader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=6, pin_memory=True)
testloader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=6, pin_memory=True)
evalloader = DataLoader(eval_data, batch_size=1, shuffle=False, num_workers=6, pin_memory=True)
return trainloader, testloader, evalloader
trainloader, testloader, evalloader = create_dataloaders(data_dir, test_pct=test_pct, batch_size=batch_size)
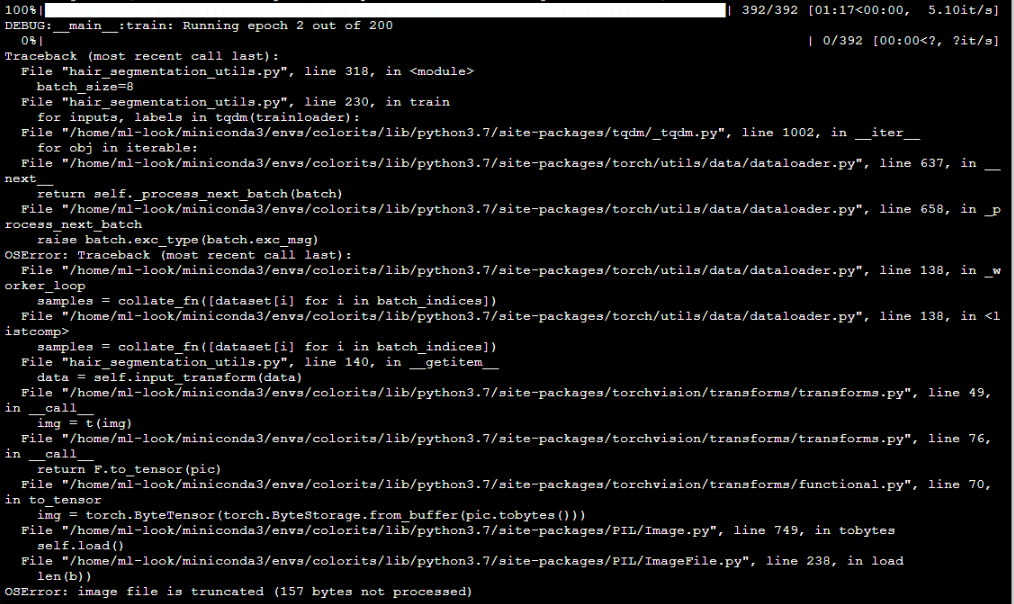
I had an idea that jpg image compression is different on win10 and linux machines depends on a lib. So i converted all jpg images to png on win10 and send zipped folder to linux machine via scp. But again the same error. First iteration on trainloader is okay, but it’s look like images get corrupted after read, because then we are trying to read same trainloader at a time, we get truncated image.
Any ideas?
hmm, i tried to do random things and found that in my ubuntu server 6 instances of python file, because num_workers = 6. So, i removed num_workers from DataLoader object creation and it worked.
Could you provide some observations why did it happen?@ptrblck
Best regards,
Alex.
@smth Any ideas? 
I’m really not sure, why PIL throws an error, if you use multiple workers.
Using
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
did not solve the error, right?
Could you upload the image somewhere? I could try to reproduce this issue on my Ubuntu machine.
I get truncated and corrupted images anyway, that doesn’t allowed for learning.
I use LFW dataset. Downloaded from here http://vis-www.cs.umass.edu/lfw/part_labels/
Thanks for the link.
I’ve downloaded the lfw_funneled dataset and it’s running fine:
path = './lfw_funneled/'
dataset = datasets.ImageFolder(
path,
transform=transforms.ToTensor()
)
# Check Dataset
for image, target in dataset:
print(target)
# Check DataLoader
loader = DataLoader(
dataset,
num_workers=6,
shuffle=False)
for data, target in loader:
print(target)
No PIL errors on my machine with 6 workers.
I’m using Ubuntu 18.04.1 LTS, and PIL 5.4.1.
Try to run more than one epoch. First epoch, as i wrote before, was fine.
it’s a clear case of a corrupted image (I’ve seen this error before).
Print the image filename as well, and inspect / redownload / delete the bad image.
I don’t get any errors for 5 epochs and still think it’s related to your image.
Did you try to redownload or delete the image as suggested?