i have a 4 GB GPU in my laptop and i’m training this network:
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.conv2 = nn.Conv2d(32, 32, 3)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv3 = nn.Conv2d(32, 64, 3)
self.conv4 = nn.Conv2d(64, 64, 3)
self.pool2 = nn.MaxPool2d(2, 2)
self.conv5 = nn.Conv2d(64, 128, 3)
self.conv6 = nn.Conv2d(128, 128, 3)
self.pool3 = nn.MaxPool2d(2, 2)
self.conv7 = nn.Conv2d(128, 256, 3)
self.conv8 = nn.Conv2d(256, 256, 3)
self.pool4 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(256*12*12,4096)
self.fc2 = nn.Linear(4096, 5)
def forward(self, input):
x = self.pool1(self.conv2(F.relu(self.conv1(input))))
x = self.pool2(self.conv4(F.relu(self.conv3(x))))
x = self.pool3(self.conv6(F.relu(self.conv5(x))))
x = self.pool4(self.conv8(F.relu(self.conv7(x))))
#flatten the tensor for the FC
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
and this is the main:
use_cuda = torch.cuda.is_available()
learning_rate = 0.001
batch_size = 5
num_epochs = 60
display_step = 10
trainset = myDataset(csv_path, root_dir)
trainloader = DataLoader(dataset=trainset,
batch_size=5,
shuffle=False,
num_workers=4,
pin_memory=True)
model = ConvNet().cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=0.0)
#scheduler_model = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=1.0)
criterion = nn.NLLLoss().cuda()
losses = []
for epoch in range(num_epochs):
loss_ = 0.
predicted = []
ground_truth = []
for batch_idx, batch in enumerate(trainloader):
data = batch['image']
labels = batch['label']
labels = labels.long()
if use_cuda:
data = Variable(data).cuda()
labels = Variable(labels).cuda()
if labels.data.size()[0] == batch_size:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, labels)
loss_ += loss.data[0]
loss.backward()
optimizer.step()
if batch_idx % display_step == 0:
print 'Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(trainloader.dataset),
100. * batch_idx / len(trainloader), loss.item())
when i try to put break statement and run only one batch it works well but when i run the whole code for the total number of epochs it gives me that error:
RuntimeError Traceback (most recent call last)
<ipython-input-5-d4fa0262e284> in <module>()
36 print 'loss',loss
37 loss_ += loss.data[0]
---> 38 loss.backward()
39 optimizer.step()
40 #torch.cuda.empty_cache()
/home/eslam/anaconda2/lib/python2.7/site-packages/torch/tensor.pyc in backward(self, gradient, retain_graph, create_graph)
91 products. Defaults to ``False``.
92 """
---> 93 torch.autograd.backward(self, gradient, retain_graph, create_graph)
94
95 def register_hook(self, hook):
/home/eslam/anaconda2/lib/python2.7/site-packages/torch/autograd/__init__.pyc in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables)
87 Variable._execution_engine.run_backward(
88 tensors, grad_tensors, retain_graph, create_graph,
---> 89 allow_unreachable=True) # allow_unreachable flag
90
91
RuntimeError: cuda runtime error (2) : out of memory at /opt/conda/conda-bld/pytorch_1524577177097/work/aten/src/THC/generic/THCStorage.cu:58
I have 2 questions:
-
I read that this is OOM however i want to understand if this error is due to some poor logic from my code or it’s just the memory could not handle the
batch_size(although i usedbatch_size1 and the error still occurs). -
should i use
torch.cuda.empty_cache()to free unneeded memory during iteration? when i writewatch nvidia-smion terminal my python PID still using the whole memory even after the code raised the error and stopped!
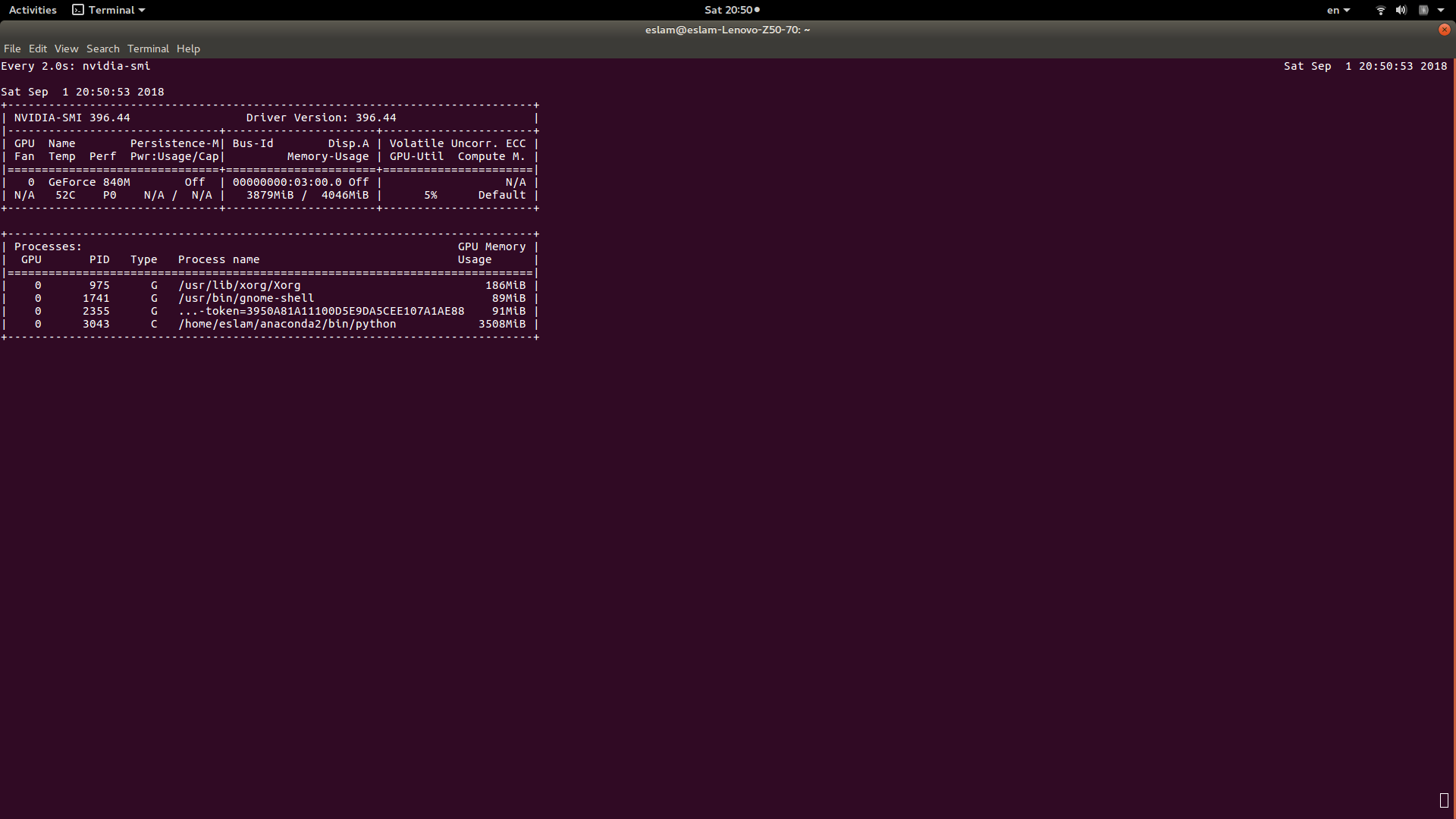
Thanks a lot!