Hey guys, I am new to ML. I tried to use InceptionV3 for 3 class output using transfer learning. I freezed all the parameters(including aux_logits= False).
My output layer:
(fc): Sequential(
(0): Linear(in_features=2048, out_features=1024, bias=True)
(1): ReLU()
(2): Dropout(p=0.3, inplace=False)
(3): Linear(in_features=1024, out_features=512, bias=True)
(4): ReLU()
(5): Dropout(p=0.3, inplace=False)
(6): Linear(in_features=512, out_features=3, bias=True)
)
I have seen in many cases there people dont use any activation for output layer. What is the reason?
I have used Softman() at output layer and CrossEntropyLoss(). I am see only decreses in train loss and val loss decreases very slowly
If you are working on a multi-class classification use case and use nn.CrossEntropyLoss, your model should output raw logits, as internally nn.CrossEntropyLoss will apply F.log_softmax and nn.NLLLoss.
Hey thanks for your reply!
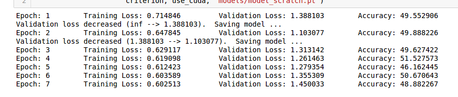
I tried to train my inception v3 but the val loss does not seem to decrease! I tried different learning rate but no luck there. I have a feeling that my model is too complex for my dataset. Any suggestions?
Your model seems to be overfitting pretty quickly, so I would suggest to add some regularization such as weight decay or increase the drop probability in your dropout layers.
Hey!
Thanks for the suggestions. I have kept the model for training with dropout(0.8) and also weight decay 0.01 and also included a scheduler for lr adjustment.
Is it possible to asses how changing the output layer from one mentioned above to given below effect:
The output layer returns the class logits in a classification setup.
Besides the training time, your model architecture and thus the use case would be changed from 1024 classes to 3 classes.