Thank you for reading my post.
My question is, how can I mitigate the small numerical errors results from input size variety to accumulate through the layers?
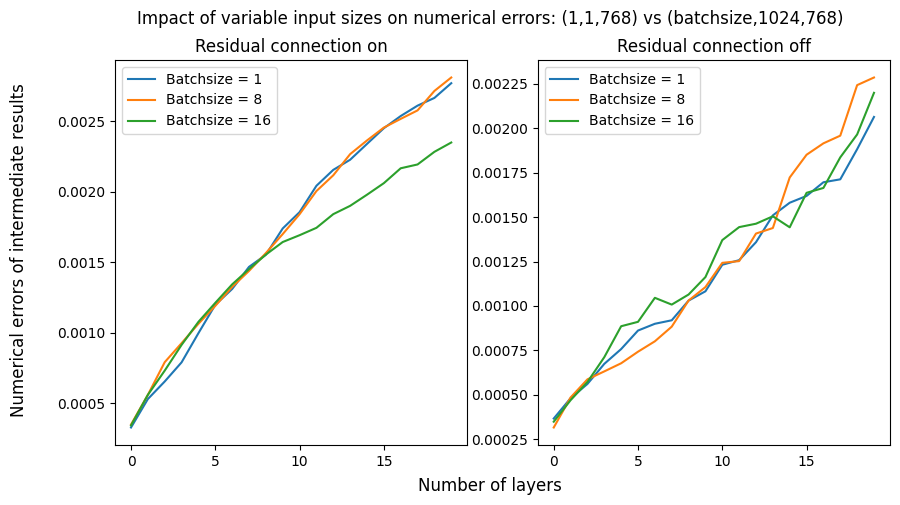
This question may not be obvious. So I will explain it below with a figure illustrating this problem.
Background:
Because of the limit of numerical accuracy, the input size (shape) influences the outputs even though the expected outputs are mathematically identical. This is explained in the doc Numerical accuracy — PyTorch 2.4 documentation. There is a quote from the doc:
’ Then (A@B)[0] (the first element of the batched result) is not guaranteed to be bitwise identical to A[0]@B[0] (the matrix product of the first elements of the input batches) even though mathematically it’s an identical computation.’
And, I suppose that such errors are so small that you can essentially ignore. However, I noticed that such errors can grow larger as the input goes through multiple layers and become large enough to affect the model’s performance.
Experiment
I instantiated a simple model with 20 feed-forard layers with (or without) residual connections. I setup a random input with the size of (batchsize, 1024, 768). The output size is expected to be the same as the input.
Suppose I am now interested only in the last row of the input (-1, -1, :), I let the model compute in two ways:
- Pass the entire input, and then slice out the last row from the output.
- Pass only the last row of the input
I stored the intermediate outputs in each layer for the experiment, and compute the difference between the two strategies. The expected results are mathematically the same; however, they are slightly different as expained above. As you can see in the figure, the small numerical errors are linearly increasing.
Question
How can I mitigate such accumulating errors? Are there any good ways to prevent this?
I am acutually facing this problem in my model with 12 decoder-only transformer layers, which has many feed-forward layers with residual connections. This phenomenon is seemingly so prominent in my case that I cannot implement KV-cache (where I only use the last row of the input).
I will appreciate it very much if someone gives me any insights into this.
=== Code ===
The experiment, and the figure can be reproduced by the codes below:
import torch
import matplotlib.pyplot as plt
# ********************
# * Model Definition *
# ********************
class TestFeedForward(torch.nn.Module):
"""Simple residual layer (Linear -> GeLU -> Linear)"""
def __init__(self, dim1, dim2):
super().__init__()
self.norm1 = torch.nn.LayerNorm(dim1)
self.norm2 = torch.nn.LayerNorm(dim1)
self.linear1 = torch.nn.Linear(dim1,dim2)
self.gelu = torch.nn.GELU()
self.linear2 = torch.nn.Linear(dim2,dim1)
def forward(self, x, residual:bool=True):
out = self.linear1(self.norm1(x))
out = self.gelu(out)
out = self.norm2(self.linear2(out))
if residual:
out = x + out
return out
class TestMod(torch.nn.Module):
"""A test module with multiple feedforward layers with residual connections.
"""
def __init__(self, n_layers:int, embed_dim:int):
super().__init__()
self.layers = torch.nn.ModuleList([TestFeedForward(embed_dim,embed_dim) for _ in range(n_layers)])
# Parameter initialization
for n, p in self.named_parameters():
if "norm" in n and "weight" in n:
torch.nn.init.constant_(p, 1)
elif "bias" in n:
torch.nn.init.constant_(p, 0)
else:
torch.nn.init.normal_(p, mean=0, std=0.2)
# Initialize intermediate results
self.register_buffer("checkpoints", None)
def forward(self, x, residual:bool=True):
out = x
for layer in self.layers:
# Forward
out = layer(out, residual=residual)
# Save the intermediate results as 'self.checkpoints'
if self.checkpoints is None:
self.checkpoints = out.unsqueeze(0)
else:
self.checkpoints = torch.cat([self.checkpoints, out.unsqueeze(0)])
return out
# **********************
# * Conduct Experiment *
# **********************
# Instantiate a model
device = "cuda" if torch.cuda.is_available() else "cpu"
model = TestMod(n_layers=20, embed_dim=768).eval().to(device)
# Compare between different batchsizes
batchsize_list = [1, 8, 16]
fig, axes = plt.subplots(1,2, figsize=(10, 5))
for i, residual in enumerate([True, False]):
for batchsize in batchsize_list:
# Try forward computation with an entire batch
b1 = torch.randn(size=(batchsize, 1024, 768),device=device)
_ = model(b1, residual = residual)
cp1 = model.checkpoints # <- this is the set of intermediate computation results
model.checkpoints = None
# Try forward computation only with the last rows (simulating KV-cache)
b2 = b1[-1:, -1:, :].clone()
_ = model(b2, residual = residual)
cp2 = model.checkpoints
model.checkpoints = None
# Compute the difference and plot
diff = (cp1[:, -1, -1, :] - cp2[:, -1, -1, :]).abs().mean(-1)
axes[i].plot(diff.tolist(), label=f"Batchsize = {batchsize}")
axes[0].set_title("Residual connection on")
axes[1].set_title("Residual connection off")
axes[0].legend()
axes[1].legend()
fig.suptitle("Impact of variable input sizes on numerical errors: (1,1,768) vs (batchsize,1024,768)")
fig.supxlabel("Number of layers")
fig.supylabel("Numerical errors of intermediate results")
plt.show()