I am working on a project that requires inputting an image and a sequence of actions and predicting the future positions of the robot as well as any collisions. I am currently having an issue with the model producing only a single set output no matter the input provided (from training set, from testing set, or random). Before the model is even trained it seems to have only one small set of outputs and only slowly diverges from its initial set of outputs during training until it has a new fixed set of outputs that again does not change depending on the input. Because of this, I do not think that it is a training problem or an over-fitting problem. I am not able to figure out what is going on so any help is greatly appreciated. Below is my model code, some test code, and some of the outputs/labels.
Model
class NavNet(nn.Module):
def __init__(self, input_shape=(3,180,320), hidden_dims=128):
super(NavNet, self).__init__()
# Constants for applying activations and loss functions only at specific locations in output tensor
collision_mask = torch.tensor([0,0,0,1]).float()
self.register_buffer('collision_mask_const', collision_mask)
bumpiness_mask = torch.tensor([0,0,1,0]).float()
self.register_buffer('bumpiness_mask_const', bumpiness_mask)
position_mask = torch.tensor([1,1,0,0]).float()
self.register_buffer('position_mask_const', position_mask)
self.input_conv = nn.Sequential(
nn.Conv2d(3,32, kernel_size=5,stride=2, padding=0),
nn.ReLU(),
nn.Conv2d(32,32,5,2),
nn.ReLU(),
nn.Conv2d(32,64,3,2),
nn.ReLU(),
nn.Flatten()
)
fc_dims = self.input_conv(torch.zeros(input_shape).unsqueeze(0)).shape[1]
self.input_fc = nn.Sequential(
nn.Linear(fc_dims,hidden_dims*3),
nn.ReLU(),
nn.Linear(hidden_dims*3, hidden_dims*2),
nn.ReLU(),
nn.Linear(hidden_dims*2, hidden_dims),
nn.ReLU(),
nn.Linear(hidden_dims, hidden_dims)
)
self.action_fc = nn.Sequential(
nn.Linear(2, 16),
nn.ReLU(),
nn.Linear(16, 16)
)
self.lstm = nn.LSTM(16, hidden_dims, batch_first=True) # 16 input size, 128 hidden size
self.output_fc = nn.Sequential(
nn.Linear(hidden_dims, 32),
nn.ReLU(),
nn.Linear(32, 4) # collision, bumpiness, x, y
)
# seq is the action sequence to be evaluated [[action 1],[action 2],[action 3]]
def forward(self,x,seq):
x = self.input_conv(x)
x = self.input_fc(x).unsqueeze(0)
actions = self.action_fc(seq)
g, hidden = self.lstm(actions, (x, x))
output = self.output_fc(g)
# apply sigmoid activation to collision probability
output = torch.sigmoid(output)*self.collision_mask_const + output*(self.bumpiness_mask_const + self.position_mask_const)
return output
# custom loss function https://github.com/gkahn13/badgr/blob/master/configs/bumpy_collision_position.py
def navnet_loss(self, model_output, target):
loss = F.binary_cross_entropy(model_output*self.collision_mask_const, target*self.collision_mask_const)
loss += F.mse_loss(model_output*self.bumpiness_mask_const, target*self.bumpiness_mask_const)
loss += F.mse_loss(model_output*self.position_mask_const, target*self.position_mask_const)
return loss
Simple Test Function
test_batch_size = 2
action_seq_length = 7
test_input = torch.rand((test_batch_size, 3,180,320))
print("Input Image : ", test_input.shape)
test_actions = torch.rand((test_batch_size, action_seq_length,2))
print("Input Actions : ", test_actions.shape)
output = navnet(test_input, test_actions)
print("Output : ", output.shape)
print(output)
torchviz.make_dot(output).render("navnet", format="png")
Output of test
Input Image : torch.Size([2, 3, 180, 320])
Input Actions : torch.Size([2, 7, 2])
Output : torch.Size([2, 7, 4])
tensor([[[ 0.0184, -0.0096, 0.0313, 0.4624],
[ 0.0205, -0.0130, 0.0311, 0.4639],
[ 0.0211, -0.0146, 0.0303, 0.4646],
[ 0.0190, -0.0147, 0.0314, 0.4652],
[ 0.0187, -0.0154, 0.0307, 0.4652],
[ 0.0201, -0.0162, 0.0316, 0.4653],
[ 0.0174, -0.0156, 0.0317, 0.4654]],
[[ 0.0187, -0.0098, 0.0298, 0.4623],
[ 0.0202, -0.0129, 0.0289, 0.4637],
[ 0.0202, -0.0142, 0.0282, 0.4645],
[ 0.0194, -0.0147, 0.0285, 0.4649],
[ 0.0189, -0.0151, 0.0279, 0.4650],
[ 0.0189, -0.0157, 0.0311, 0.4652],
[ 0.0208, -0.0164, 0.0312, 0.4652]]], grad_fn=<AddBackward0>)
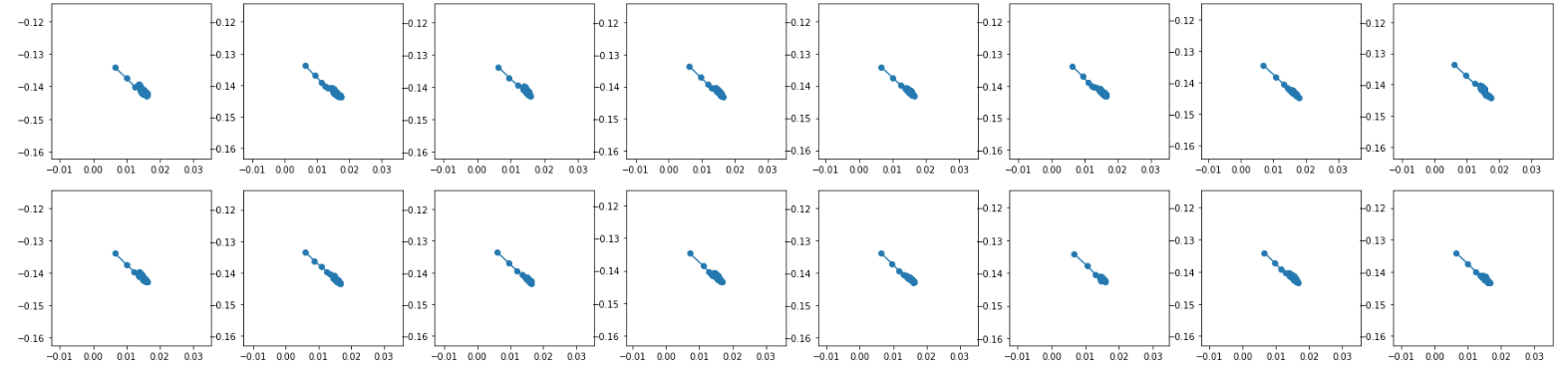
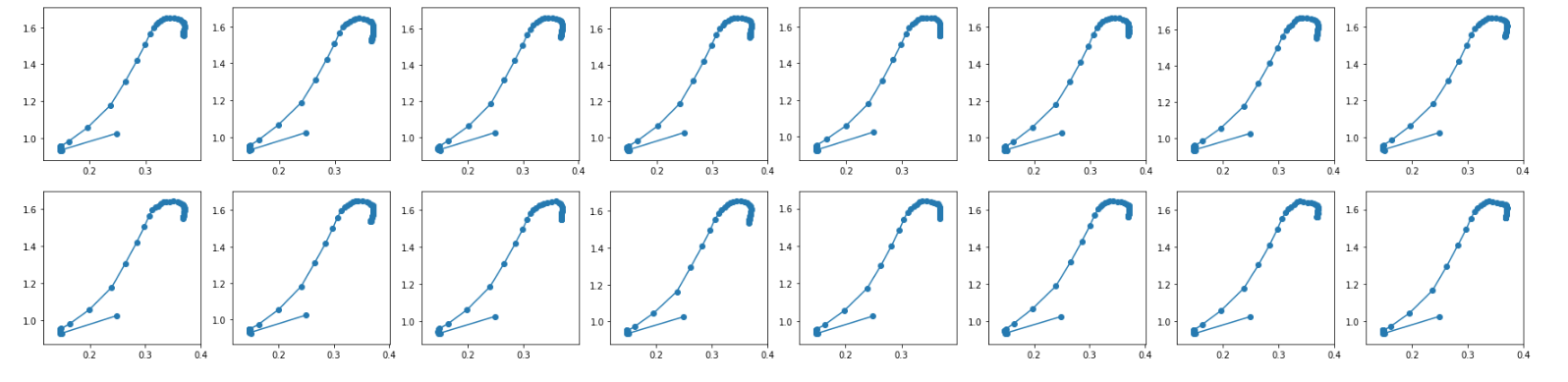
After a short training period the output ends up something like the following when visualized. On the top are the labels and the bottom is the output of the network. I have double and triple checked to make sure that everything in way of the data is being processed and passed in correctly. Before any training, the output has a similar fixedness but is usually just more bunched up around a particular point.
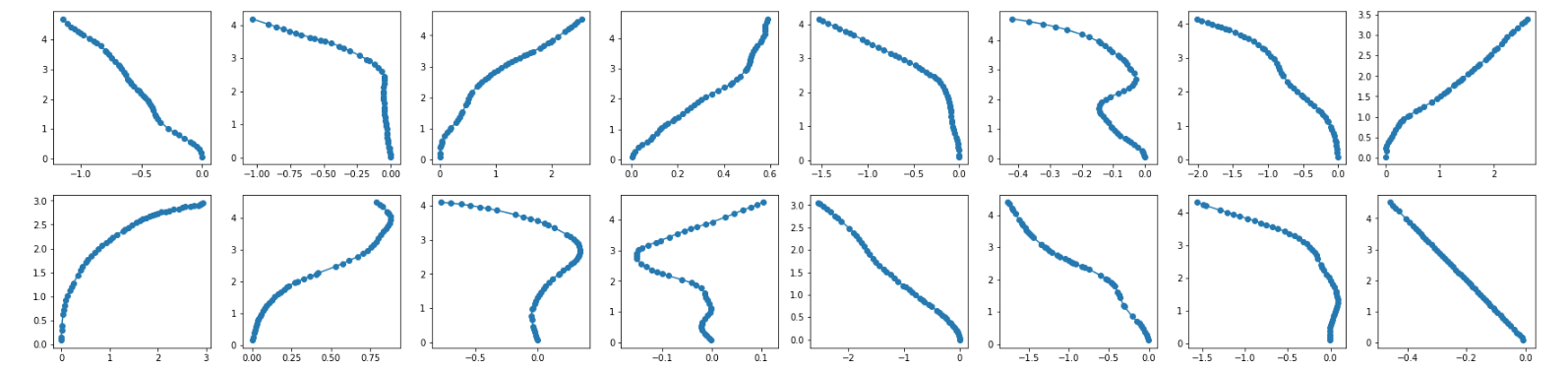
edit 1 : Here is the networks output from different inputs without any training