Hello.
I’m training CNN models now.
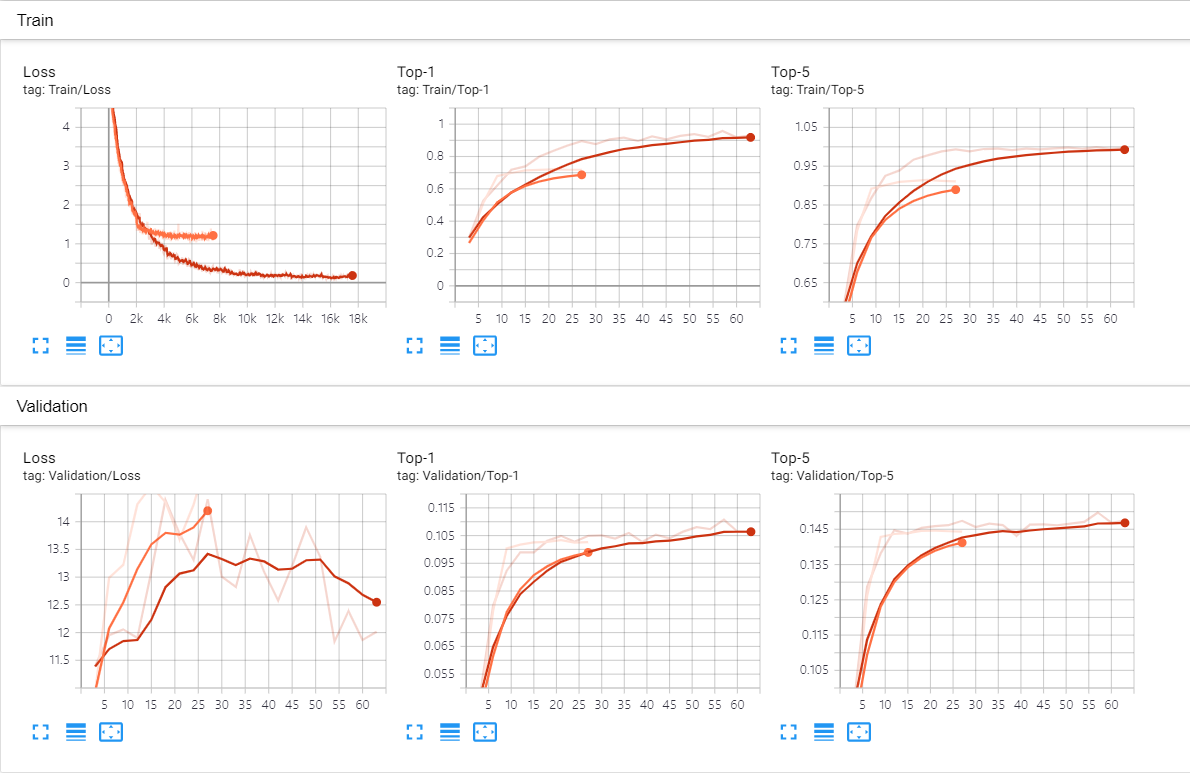
I got the result, but it seems overfitting.(good Accuracy on training set, bad Accuracy on validation set)
Here’s my code. I trained GoogLeNet, but when I trained ResNet34, the result was also overfitting.
Some Ignite code are used to train more easily, but I think this is not main problem.
'''
training-GoogLeNet.py
This file is for training GoogLeNet
'''
# Import modules
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn import DataParallel
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import models, datasets, transforms
from ignite.engine import Events, create_supervised_trainer, create_supervised_evaluator
from ignite.metrics import Accuracy, TopKCategoricalAccuracy, Loss
from ignite.handlers import ModelCheckpoint, EarlyStopping
from ignite.contrib.handlers.param_scheduler import LRScheduler
import matplotlib.pyplot as plt
from PIL import Image, ImageFile
# Error preventing
torch.multiprocessing.set_sharing_strategy('file_system')
ImageFile.LOAD_TRUNCATED_IMAGES = True
# CUDA Setting
cuda = True if torch.cuda.is_available() else False
if cuda == True:
device = torch.device('cuda')
device_ids = [0, 1, 2, 3]
else:
device = torch.device('cpu')
# TensorBoard Setting
tensorboard_log_directory = 'runs/GoogLeNet training'
writer = SummaryWriter(tensorboard_log_directory)
# Model Checkpointer Setting
checkpointer = ModelCheckpoint('models/GoogLeNet', 'GoogLeNet', save_interval = 3, n_saved = 5)
# Training Setting
max_epoch = 70
# Dataset: ImageNet
ImageNet_directory = ~~ (ImageNet directory)
ImageNet_transform = transforms.Compose([
transforms.Resize(320),
transforms.CenterCrop(299),
transforms.ToTensor(),
# ***Image Normalization to avoid overfitting***
transforms.Normalize(mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])
])
if cuda == True:
batch_size = 100 * len(device_ids)
else:
batch_size = 10
ImageNet_train_data = datasets.ImageNet(root = ImageNet_directory, download = False, split = 'train', transform = ImageNet_transform)
ImageNet_train_dataloader = DataLoader(ImageNet_train_data, batch_size = batch_size, shuffle = True, num_workers = 16)
ImageNet_val_data = datasets.ImageNet(root = ImageNet_directory, download = False, split = 'val', transform = ImageNet_transform)
ImageNet_val_dataloader = DataLoader(ImageNet_val_data, batch_size = batch_size, shuffle = True, num_workers = 16)
# Model: GoogLeNet, not pre-trained(we're gonna train)
GoogLeNet = models.inception_v3(pretrained = False, progress = True, aux_logits = False)
if cuda == True: #Ignite Engine doesn't use data-parallelism(only 1 GPU), so manually distributes the model
GoogLeNet = DataParallel(GoogLeNet, device_ids = device_ids)
# loss function
loss = nn.CrossEntropyLoss()
# optimizer: "Our training used asynchronous stochastic gradient descent with 0.9 momentum"
# ***Also, I used weight_decay(regularization) to avoid overfitting***
optimizer = optim.SGD(GoogLeNet.parameters(), lr = 0.1, momentum = 0.9, weight_decay = 0.0001)
# learning rate scheduler: "fixed learning rate schedule (decreasing the learning rate by 4% every 8 epochs)"
scheduler = LRScheduler(optim.lr_scheduler.StepLR(optimizer, step_size = 8, gamma = 0.04))
# Define training, evaluating Engine
trainer = create_supervised_trainer(GoogLeNet, optimizer, loss, device = device)
evaluator = create_supervised_evaluator(GoogLeNet, metrics = {'Top-1': Accuracy(),
'Top-5': TopKCategoricalAccuracy(k = 5),
'Loss': Loss(loss)}, device = device)
# Register Events
## train loss logger
def log_train_loss(trainer):
writer.add_scalar('Train/Loss', trainer.state.output, global_step = trainer.state.iteration)
trainer.add_event_handler(Events.ITERATION_COMPLETED, log_train_loss)
## general metrics logger
validate_every = 3
def log_metrics(trainer):
if trainer.state.epoch % validate_every == 0:
# validate training set
evaluator.run(ImageNet_train_dataloader)
metrics = evaluator.state.metrics
writer.add_scalar('Train/Top-1', metrics['Top-1'], global_step = trainer.state.epoch)
writer.add_scalar('Train/Top-5', metrics['Top-5'], global_step = trainer.state.epoch)
# validate validation set
evaluator.run(ImageNet_val_dataloader)
metrics = evaluator.state.metrics
writer.add_scalar('Validation/Top-1', metrics['Top-1'], global_step = trainer.state.epoch)
writer.add_scalar('Validation/Top-5', metrics['Top-5'], global_step = trainer.state.epoch)
writer.add_scalar('Validation/Loss', metrics['Loss'], global_step = trainer.state.epoch)
trainer.add_event_handler(Events.EPOCH_COMPLETED, log_metrics)
## scheduler
trainer.add_event_handler(Events.EPOCH_STARTED, scheduler)
## model checkpointer
trainer.add_event_handler(Events.EPOCH_COMPLETED, checkpointer, {'EPOCH': GoogLeNet})
## early stopper
def score_function(engine):
validation_loss = engine.state.metrics['Loss']
return -validation_loss
earlystopper = EarlyStopping(patience = 5, score_function = score_function, trainer = trainer)
evaluator.add_event_handler(Events.COMPLETED, earlystopper)
# run Engine
if __name__ == '__main__':
trainer.run(ImageNet_train_dataloader, max_epoch)
I tried to avoid overfitting by normalization and regularization, but the result was…
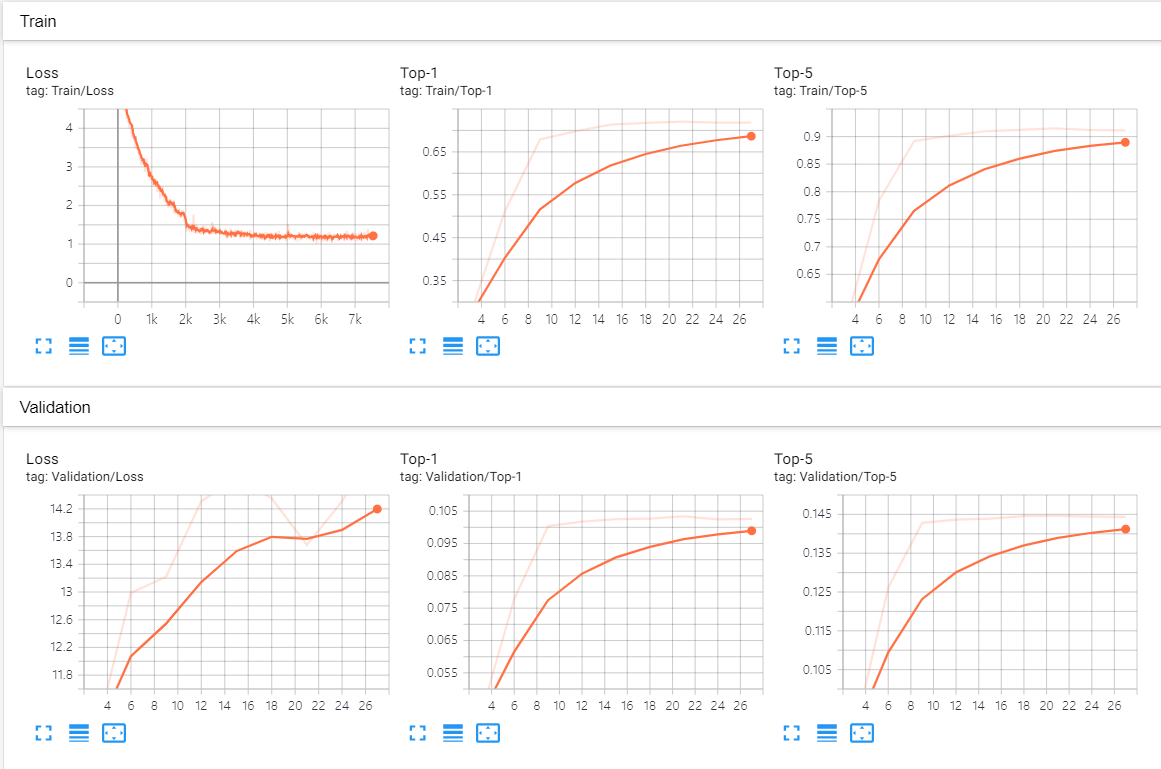
As you can see, Top-1 and Top-5 result on training set are reasonable(70%, 90% Accuracy each), but on validation set, Top-1 and Top-5 Accuracy are 10%, 14% each, also Loss is increasing.
What’s the problem with my code? Please someone helps me.
Any opinions are welcomed. Thanks.