Hi Michael!
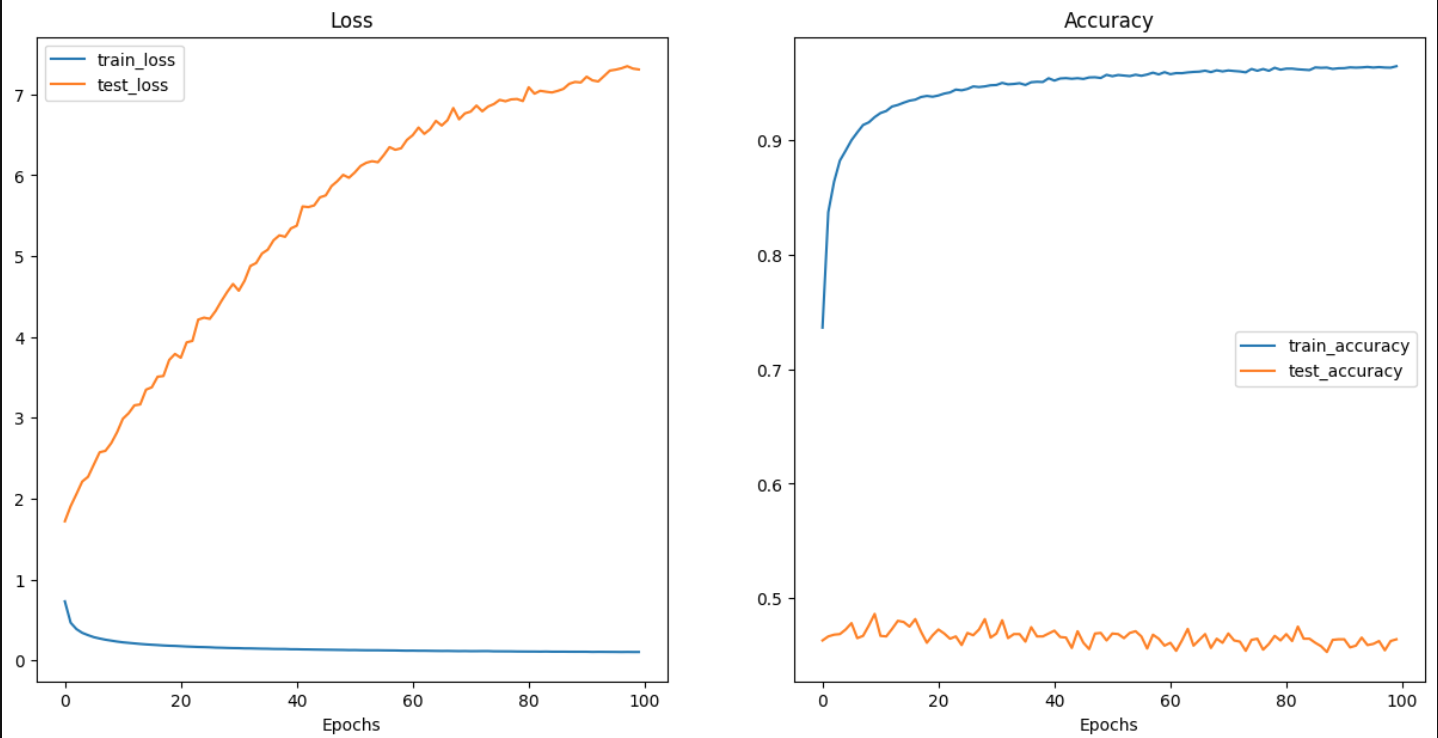
At first glance, it does look like your model is overfitting – the training loss
is going down while the validation loss is going up, and so on.
However, on closer inspection, the graphs look fishy to me.
You add a new, randomly-initialized head to your model. Therefore, before
any training or fine-tuning, your model should be making random guesses,
regardless of how well your pre-trained “backbone” matches your use case.
With an eight-class classification problem (with about the same number of
data samples in each class), random guesses will produce an accuracy of
12.5%.
In your accuracy graph, your initial training accuracy (this is presumably the
value after either no training or one epoch of training, depending on when you
take your accuracy snapshot) is over 70%, which seems surprisingly high.
Furthermore, your validation accuracy, although not as high, is still something
like 45%, which is also much better than random guessing.
Your loss values also look fishy. Your validation loss starts out worse than
your training loss, and immediately goes up. Even if your graphs start after
the first epoch of training, it seems highly unlikely that your model (specifically
its head) could have overfit after a single epoch of training (during which it
would have seen each of the approximately 18,000 training images only once).
The results just don’t look sensible.
Again, depending on how your code is organized, the initial points on your
graphs might be after training for an epoch. If so, what are your training
and validation losses and accuracies before training (that is, immediately
after installing your randomly-initialized head)? At this point, your training
and validation losses should be nearly equal and your training and validation
accuracies should both be approximately 12.5%.
Last, things like BatchNorm and Dropout behave differently in train
and eval mode. To make sure that you are making an apples-to-apples
comparison, it probably makes sense to plot training and validation losses
and accuracies all computed with your model running in eval mode.
Best.
K. Frank