Here is a simple example of computing attention scores (rather weights before multiplying the q,k product by values.) We have two sequenes, one of which is padded with 0. Attention mask will be dimension 10X10. And when applied to scores tensor it works as expected by changing all values on upper diagonal to 0 for both cases in this batch of 2.
The padding mask will be dimension 2X10, or rather 2X1X10 after unsqueeze(1) so it can be applied to each case in the batch. If we apply this mask to the scores before the attention mask, the last 5 columns of the score tensor of the first case in the batch change to -inf. Score tensor for the second case remains unchanged as expected.
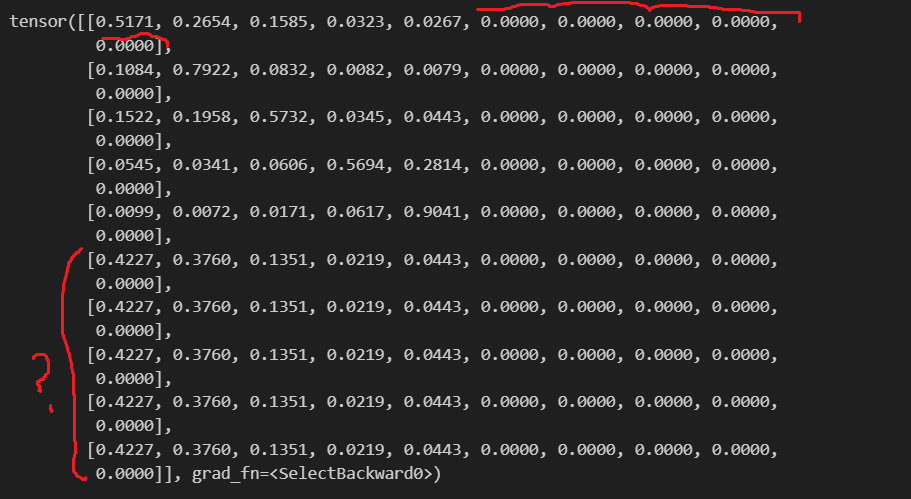
But shouldn’t the last 5 columns AND the last 5 rows in the first tensor score change to -inf? Since the score matrix is essentially a similarity matrix between each element in the sequence, wouldn’t both padded rows and columns zero out? Image of the first case score tensor below.
x=torch.tensor([[1,2,3,4,5,0,0,0,0,0],[1,2,3,4,5,6,7,8,9,10]])
embed=torch.nn.Embedding(11,12)
q=embed(x)
k=q
# attention mask
atten_mask=np.triu(np.ones((1, 10, 10)), k=1).astype('uint8')
atten_mask = (torch.from_numpy(atten_mask) == 0)
# padding mask
pad_mask=(x!=0)
scores = torch.matmul(q, k.transpose(-2, -1)) / 12 ** 0.5
# masked scores, applying pad mask only
pad_mask = pad_mask.unsqueeze(1)
scores.masked_fill_(pad_mask == 0, -np.inf)
#scores.masked_fill_(atten_mask == 0, -np.inf)
F.softmax(scores, dim=-1)[0]