Hello everyone,
I wanted to create a network like the below image. How can I define multiple data_loaders on PyTorch and feed it to the network like below? How can I concatenate the parallel models to have such a structure? What if I wanted to have a weighted loss of the different models?
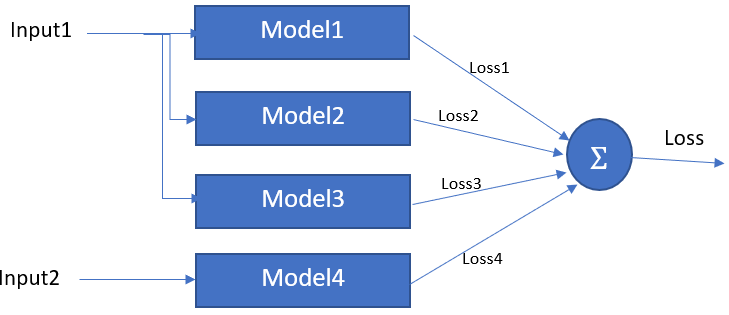
You can (1) look at the tutorial of distributed parallel training (for the sake of different models on different device and your loss computation), and (2) imitate the structure of parameter server to keep the model possessing the same set of parameters.
I have written a simple code
import torch.utils.data as data
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class MyDataSet(torch.utils.data.Dataset):
def __init__(self, numpyData,numpyTarget):
self.data = numpyData
self.target = numpyTarget
def __len__(self):
return(self.data.shape[0])
def __getitem__(self, idx):
return((self.data[idx],self.target[idx]))
target=np.random.randint(2,size=(100)).astype(np.float32)
myDataSet1=MyDataSet(np.random.rand(100,5).astype(np.float32),target)
myDataSet2=MyDataSet(np.random.rand(100,8).astype(np.float32),target)
dataLoader1 = data.DataLoader(myDataSet1, batch_size=10, shuffle=False, num_workers=0)
dataLoader2 = data.DataLoader(myDataSet2, batch_size=10, shuffle=False, num_workers=0)
class model1(nn.Module):
def __init__(self):
super(model1,self).__init__()
self.l1=nn.Linear(5,3)
self.l2=nn.Linear(3,1)
def forward(self,x):
out=self.l1(x)
out=self.l2(out)
return(out)
class model2(nn.Module):
def __init__(self):
super(model2,self).__init__()
self.l1=nn.Linear(5,3)
self.l2=nn.Linear(3,1)
def forward(self,x):
out=self.l1(x)
out=self.l2(out)
return(out)
class model3(nn.Module):
def __init__(self):
super(model3,self).__init__()
self.l1=nn.Linear(5,3)
self.l2=nn.Linear(3,1)
def forward(self,x):
out=self.l1(x)
out=self.l2(out)
return(out)
class model4(nn.Module):
def __init__(self):
super(model4,self).__init__()
self.l1=nn.Linear(8,5)
self.l2=nn.Linear(5,3)
self.l3=nn.Linear(3,1)
def forward(self,x):
out=self.l1(x)
out=self.l2(out)
out=self.l3(out)
return(out)
model1Obj=model1()
model2Obj=model2()
model3Obj=model3()
model4Obj=model4()
opt = optim.Adam(list(model1Obj.parameters()) + list(model2Obj.parameters()) + list(model3Obj.parameters()) + list(model4Obj.parameters()), lr=0.001)
criterion = nn.MSELoss()
epochs=100
for epoch in range(epochs):
totalLoss=0
for step, ((x1, y1),(x2,y2)) in enumerate(zip(dataLoader1, dataLoader2)):
# Initialization
model1Obj.zero_grad()
model2Obj.zero_grad()
model3Obj.zero_grad()
model4Obj.zero_grad()
output = model1Obj(x1)
loss1 = criterion(output, y1)
output = model2Obj(x1)
loss2 = criterion(output, y1)
output = model3Obj(x1)
loss3 = criterion(output, y1)
output = model4Obj(x2)
loss4 = criterion(output, y2)
totalLoss=loss1 + loss2 + loss3 + loss4
totalLoss.backward()
opt.step()
if(step%5==0 and epoch%10==0):
print("Epoch {0} Step {1} TotalLoss {2}".format(epoch,step,totalLoss))
Hope this helps