Hello all!
I have been recently running into troubles while attempting to train a pytorch nn.Module model, hopefully someone has knowledge on the subject. Specifically, the model was working perfectly before the GPU(A1000) being used was carved up into a set of 7 5GB MIG’s. Now, if I keep the same training batch_size defined when the GPU was whole, I get an OOM error immediately. In order to avoid the OOM error I have been forced to reduce the batch size by more than half (from 512 - 200). Because of this, training takes too long because I have a specific time window in which in needs to be trained in. Unfortunately, I can’t restore the GPU to its whole self… I have access, and am forced to use 3 MIG’s. However when I train with these 3 MIG’s, only 1 of them is visible to CUDA, so I can only use 5GB of gpu instead of the potential 15. I don’t know if its possible to simultaneously utilize 3 MIG’s during training in pytorch, I have looked through the web and couldn’t find anything that helped. If anyone has any thoughts, please share!
I will include everything I have tried so far and some more environment information below. If there is anyone that has knowledge on the subject, advice would be much appreciated.
NVIDIA environment:
nvidia-smi
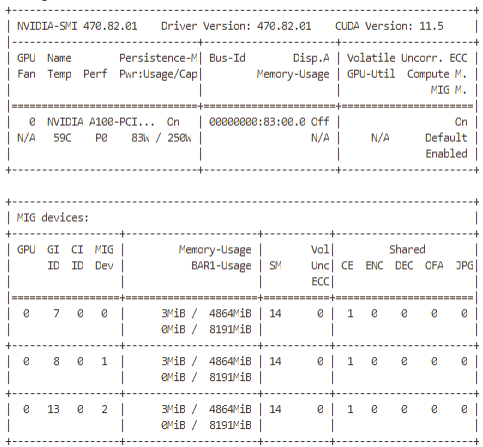
nvidia-smi -L
GPU 0: NVIDIA A100-PCIE-40GB (UUID: GPU-27db93ee-466f-3211-e58c-0be229039886)
MIG 1g.5gb Device 0: (UUID: MIG-ed8512b7-4b1a-548c-8776-f77a249cb9d1)
MIG 1g.5gb Device 1: (UUID: MIG-55f40d40-f9fd-5605-a070-4815b338e7c2)
MIG 1g.5gb Device 2: (UUID: MIG-8c3a60ee-f405-542a-a32d-5e12ebcc4dae)
Pytorch environment:
python -m torch.utils.collect_env
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.10.5 | packaged by conda-forge | (main, Jun 14 2022, 07:04:59) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.71.1.el7.x86_64-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.5.119
GPU models and configuration:
GPU 0: NVIDIA A100-PCIE-40GB
MIG 1g.5gb Device 0:
MIG 1g.5gb Device 1:
MIG 1g.5gb Device 2:
Nvidia driver version: 470.82.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] pytorch-memlab==0.2.4
[pip3] torch==1.11.0+cu113
[conda] blas 1.0 mkl defaults
[conda] cudatoolkit 11.4.2 h7a5bcfd_10 defaults
[conda] mkl 2022.1.0 h84fe81f_915 defaults
[conda] numpy 1.23.1 pypi_0 pypi
[conda] pytorch-memlab 0.2.4 pypi_0 pypi
[conda] pytorch-mutex 1.0 cpu pytorch
[conda] torch 1.11.0+cu113 pypi_0 pypi
Number of parameters
total_num of parameters: 533216
total_num of TRAINABLE parameters: 533216
Tried:
wrapping model in DataParallel
model = nn.DataParallel(model)
passing MIG names with python call
CUDA_VISIBLE_DEVICES=“MIG-GPU-ed8512b7-4b1a-548c-8776-f77a249cb9d1,MIG-GPU-55f40d40-f9fd-5605-a070-4815b338e7c2,MIG-GPU-8c3a60ee-f405-542a-a32d-5e12ebcc4dae” python main.py