Keywords: Mixture-of-Experts, CUDA Streams, Parallelism
One-liner: Attempting to execute distinct experts each with their own disjoint subset of tokens concurrently with CUDA Streams.
Expectation: Reduction in latency times for inference.
Hardware/Software. nvcr.io/nvidia/pytorch:24.04-py3, single V100 32GB, DGX1 (again only using 1 of the 8)
Note: Realised after composing that I am only able to post a single screenshot, so you will have to scroll to the replies for some.
Full Post
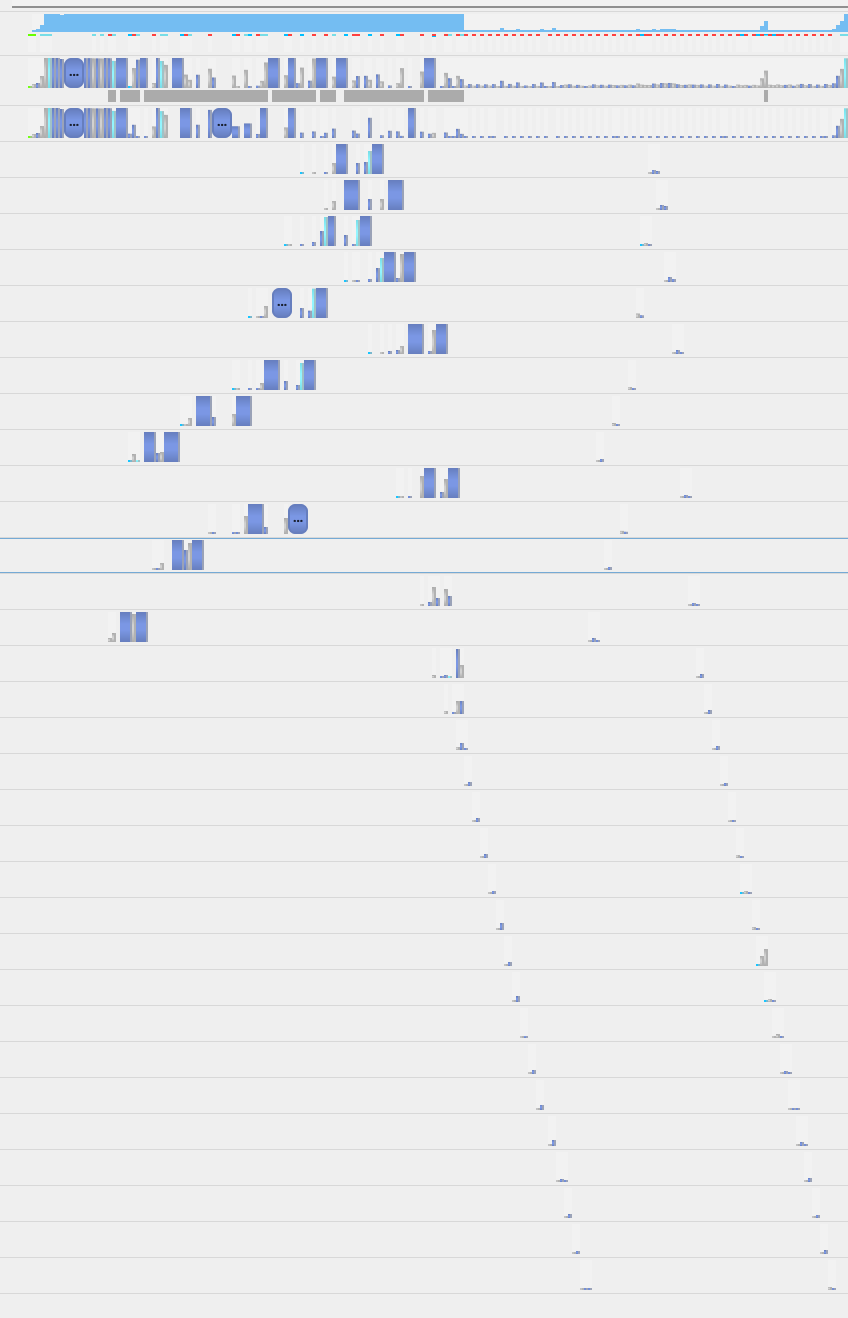
I am currently working with the SwitchTransformer model and began tracing its execution using Nsys. What I have noticed was that the different experts execute sequentially. This is surprising to me since 1. these experts do not depend on one another and 2. GPUs are massively parallel and I would expect it have no problem running an extra matrix multiplication at the same time.
Here is a showcase of the sequential execution. (Reply)
Here we see the execution of a batch through the first two blocks of the encoder. One can notice that the block without MoE is significantly quicker even though it does the same computation (the gating function is very small). The second block, you can notice the execution of all 64 experts, sequentially causing a major slowdown.
I want to reduce the time for a forward pass through a block with MoE. I figured the best approach is to find a way to run the experts concurrently since they do not depend on each other.
I firstly did a simple change to the HuggingFace SwitchTransformer model.
for idx, expert in enumerate(self.experts.values()):
token_indices = router_mask[:, :, idx].bool()
with torch.cuda.stream(self.cuda_streams[idx]):
next_states[token_indices] = expert(hidden_states[token_indices]).to(next_states.dtype)
At model creation I create a stream for each expert and then simply index in when deciding which stream to use.
(Reply). The result is that they run on separate streams although they appear to still be running sequentially – just on different streams. Furthermore inference takes 68% longer.
Furthermore was curious if the assignment was causing the serialised order so I just throw away the values.
with torch.cuda.stream(self.cuda_streams[idx]):
# Don't care abt model acc, so throw away the computation result
expert(hidden_states[token_indices.clone()])
This does start to get some kernels executing concurrently. (Reply)
However still inference takes 42% longer than serial execution.
I was thinking maybe it is an issue of having too many streams so I reduced it to two.
for idx, expert in enumerate(self.experts.values()):
token_indices = router_mask[:, :, idx].bool()
if idx % 2 == 0:
with torch.cuda.stream(self.cuda_streams[0]):
expert(hidden_states[token_indices.clone()])
else:
with torch.cuda.stream(self.cuda_streams[1]):
expert(hidden_states[token_indices.clone()])

The overlap is still not great and the overhead of using streams comes at increasing inference by 20% over the base serial execution.
Action
If anyone has more experience or knowledge, do please let me know on how to tackle this problem.